
Redis 缓存一致性
Redis 与 MySQL 数据一致性是指在同时使用这两种数据库时,确保两者存储的同一份数据在逻辑上保持同步,避免出现数据差异的问题,Redis 作为缓存层,MySQL 作为存储层,如何保证两者数据一致性是一个重要的问题。本文将详细分析几种常见方案,探讨可能遇到的问题。
1. 一致性解读
强一致性:写进去的数据是什么,读出来的数据就是什么,对性能影响最大;
弱一致性:数据写入成功后,系统不保证能立刻读出最新的数据,也不承诺多久之后数据可以达到一致,但保证到某个时间级别后,数据能达到一致;
最终一致性:最终一致性是弱一致性的一个特例,最终一致性同样只保证数据写入成功后,在某个时间点后数据会达到一致。这个系统无法保证强一致性的时间片段被称为不一致窗口。不一致时间窗口的时间长短取决于很多因素,比如副本个数、网络延迟、系统负载等。
最终一致性是弱一致性中非常受大众推崇的一种一致性模型,也是目前业界在大型分布式系统的数据一致性上比较推崇的模型
2. 缓存使用场景
对于大部分系统而言,高并发常见于读数据的场景,对于此场景我们可以使用缓存提升数据查询速度。当我们使用 Redis 作缓存的时候,常见场景如下所示:
缓存存在
如果数据在缓存中存在,则直接从缓存返回数据至应用,无需查询数据库 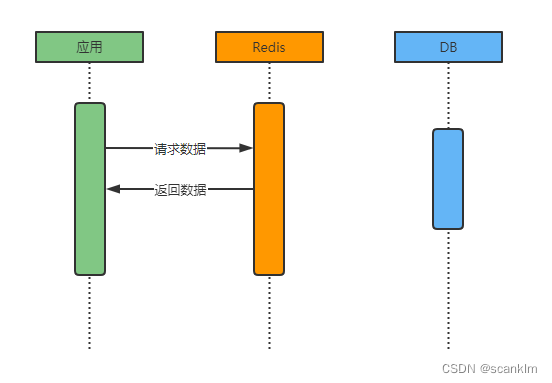
缓存不存在
如果数据在缓存中不存在,则需查询数据库获取数据并更新缓存。 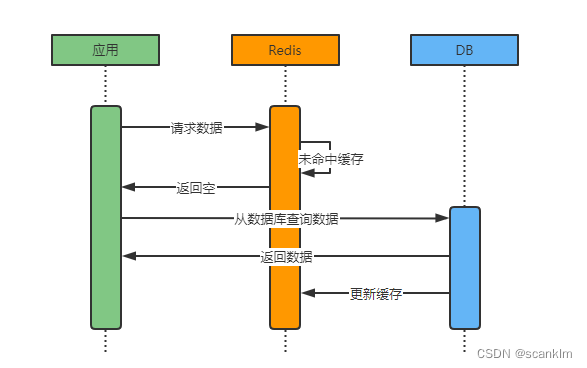
对于大部分系统而言最终数据都会存储在数据库中,也就是系统需已数据库中数据为准,那么对于上图缓存存在的场景下,当数据库中的数据发生变化时,就可能会出现数据不一致的问题。
实际情况下考虑网络、操作、异常等种种因素,根本无法保证可以同时更新所有副本数据使得数据保持一致。因此,如何在最大程度上保证各副本数据一致的同时也不影响系统性能,成了各系统需要均衡的问题。
3. 数据同步策略
3.1 先删除缓存再更新数据库
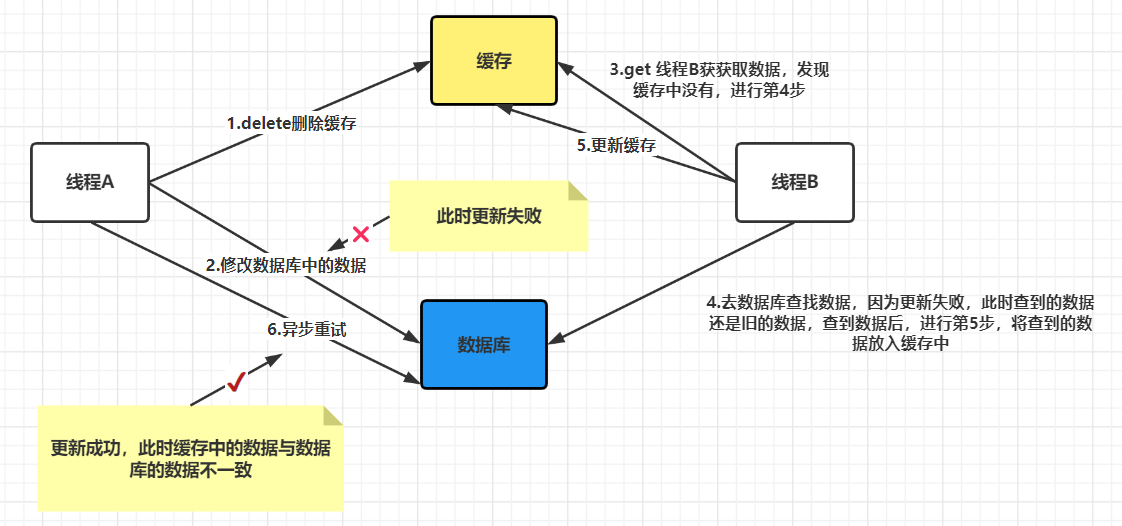
如上图,是先删除缓存再更新数据库,在出现失败时可能出现的问题:
- 线程 A 删除缓存成功,线程 A 更新数据库失败;
- 线程 B 从缓存中读取数据;由于缓存被删,进程 B 无法从缓存中得到数据,进而从数据库读取数据;此时数据库中的数据更新失败,线程 B 从数据库成功获取旧的数据,然后将数据更新到了缓存。
- 最终,缓存和数据库的数据是一致的,但仍然是旧的数据
- 代码示例
@Service
@Transactional
public class UserService {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
@Autowired
private UserMapper userMapper;
private static final String USER_CACHE_PREFIX = "user:";
/**
* 先删除缓存再更新数据库
*/
public void updateUserWithCacheDeleteFirst(User user) {
String cacheKey = USER_CACHE_PREFIX + user.getId();
try {
// 1. 先删除缓存
redisTemplate.delete(cacheKey);
// 2. 更新数据库
userMapper.updateById(user);
} catch (Exception e) {
// 如果更新数据库失败,缓存已经被删除,需要重新加载
log.error("更新用户失败,用户ID: {}", user.getId(), e);
throw new RuntimeException("更新用户失败", e);
}
}
}
- 结论 所以这种方式风险很大,一般不会推荐。
3.2 先更新数据库再删除缓存
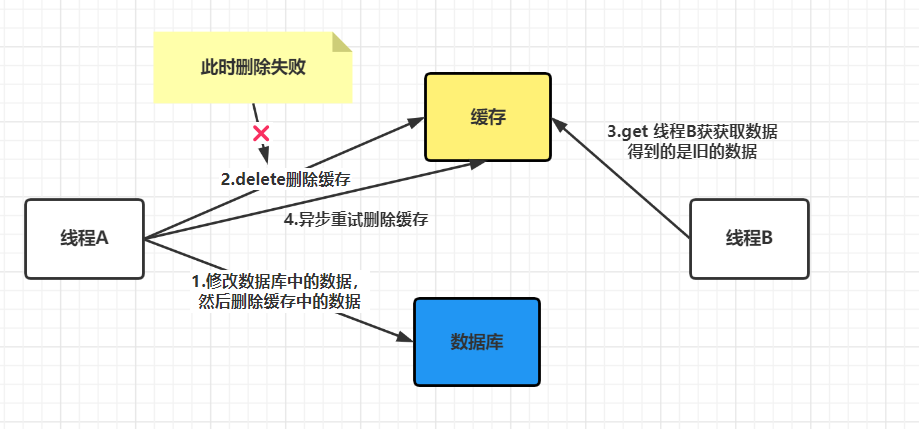
如上图,是先更新数据库再删除缓存,在出现失败时可能出现的问题:
- 线程 A 更新数据库成功,线程 A 删除缓存失败;
- 线程 B 读取缓存成功,由于缓存删除失败,所以线程 B 读取到的是缓存中旧的数据。
- 最后线程 A 删除缓存成功,有别的线程访问缓存同样的数据,与数据库中的数据是一样。
- 最终,缓存和数据库的数据是一致的,但是会有一些线程读到旧的数据。
- 代码示例
@Service
@Transactional
public class UserService {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
@Autowired
private UserMapper userMapper;
private static final String USER_CACHE_PREFIX = "user:";
/**
* 先更新数据库再删除缓存
*/
public void updateUserWithDbFirst(User user) {
String cacheKey = USER_CACHE_PREFIX + user.getId();
try {
// 1. 先更新数据库
userMapper.updateById(user);
// 2. 删除缓存
redisTemplate.delete(cacheKey);
} catch (Exception e) {
log.error("更新用户失败,用户ID: {}", user.getId(), e);
throw new RuntimeException("更新用户失败", e);
}
}
}
- 结论 这种方式的好处是逻辑简单,坏处是高并发下依然可能出现短暂不一致。比如删缓存那一瞬间,别的线程查到的还是旧数据。一般能容忍就行,如果对一致性要求极高,那就得再上别的策略。
3.3 延时双删
上面我们提到,如果是先更新数据库、在删除缓存,在删缓存那一瞬间,别的线程查到的还是旧数据,延迟双删可以大幅减少脏数据的概率。延时双删的基本思路如下:
- 代码示例
@Service
@Transactional
public class UserService {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
@Autowired
private UserMapper userMapper;
@Autowired
private ThreadPoolTaskExecutor taskExecutor;
private static final String USER_CACHE_PREFIX = "user:";
/**
* 延时双删策略
*/
public void updateUserWithDelayedDoubleDelete(User user) {
String cacheKey = USER_CACHE_PREFIX + user.getId();
try {
// 1. 更新数据库
userMapper.updateById(user);
//2. 第一次删除缓存
redisTemplate.delete(cacheKey);
// 3. 异步延时删除缓存
taskExecutor.execute(() -> {
try {
Thread.sleep(1000); // 延时1秒
redisTemplate.delete(cacheKey);
log.info("延时删除缓存成功,key: {}", cacheKey);
} catch (Exception e) {
log.error("延时删除缓存失败,key: {}", cacheKey, e);
}
});
} catch (Exception e) {
log.error("更新用户失败,用户ID: {}", user.getId(), e);
throw new RuntimeException("更新用户失败", e);
}
}
}
结论
这样做的目的就是防止「刚更新完数据库时,另一个线程把旧数据写回缓存」的情况。延迟双删可以大幅减少脏数据的概率。 当然,这不是 100% 保险,但在多数场景下够用了。
4. 利用消息队列进行删除的补偿
先更新数据库,后删除缓存这⼀种情况也会出现问题,比如更新数据库成功了,但是在删除缓存的阶段出错了没有删除成功,那么此时再读取缓存的时候每次都是错误的数据了。
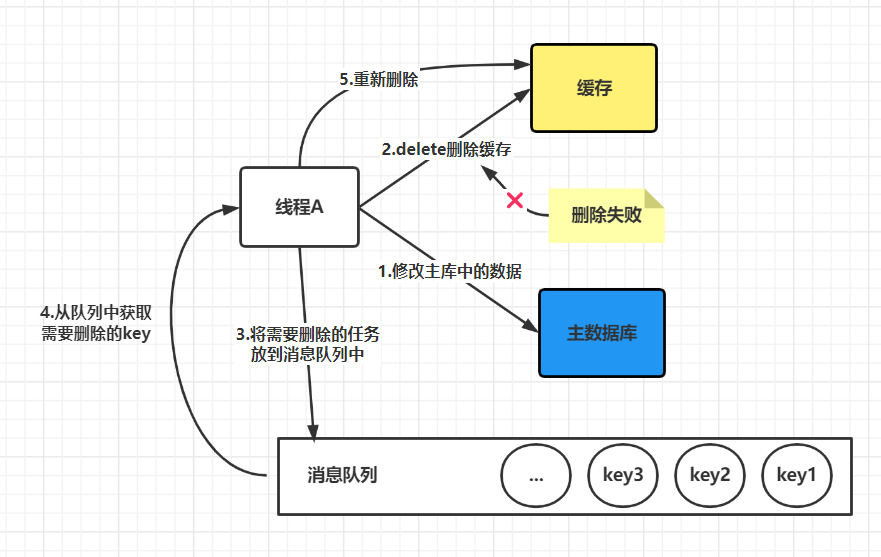
此时解决方案就是利用消息队列进行删除的补偿。具体的业务逻辑⽤语⾔描述如下:
- 请求 线程 A 先对数据库进行更新操作;
- 在对 Redis 进行删除操作的时候发现报错,删除失败;
- 此时将 Redis 的 key 作为消息体发送到消息队列中;
- 系统接收到消息队列发送的消息后再次对 Redis 进行删除操作;
但是这个方案会有⼀个缺点就是会对业务代码造成大量的侵入,深深的耦合在⼀起,所以这时会有⼀个优化的方法,我们知道对 Mysql 数据库更新操作后再 binlog 日志中我们都能够找到相应的操作,那么我们可以订阅 Mysql 数据库的 binlog 日志对缓存进行操作。
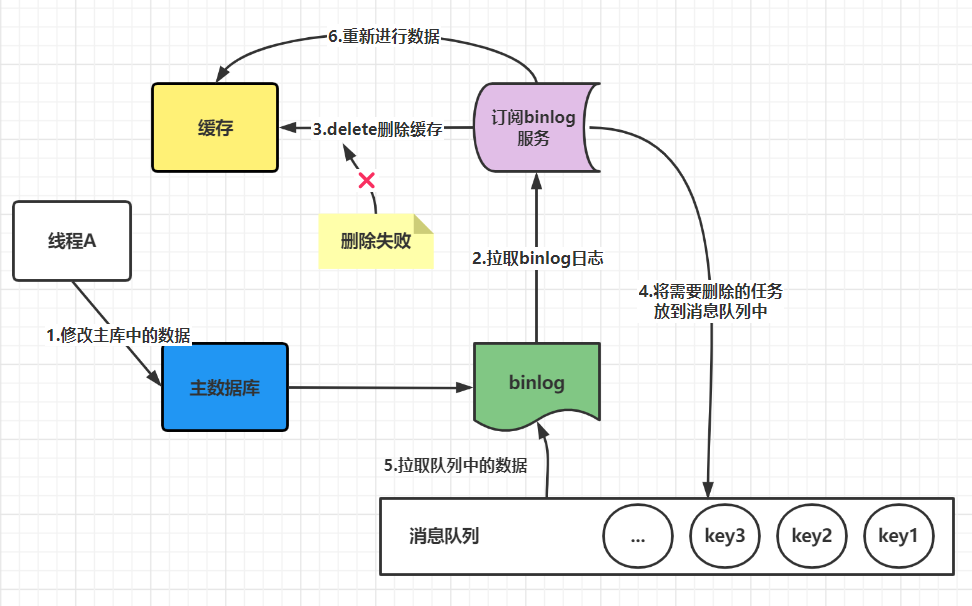
- 代码示例
@Component
public class CacheDeleteCompensation {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
@Autowired
private RabbitTemplate rabbitTemplate;
private static final String CACHE_DELETE_QUEUE = "cache.delete.queue";
/**
* 带补偿机制的缓存删除
*/
public void deleteCacheWithCompensation(String cacheKey) {
try {
// 尝试删除缓存
Boolean deleted = redisTemplate.delete(cacheKey);
if (!deleted) {
log.warn("缓存删除失败,发送到消息队列进行补偿,key: {}", cacheKey);
// 发送到消息队列进行补偿
rabbitTemplate.convertAndSend(CACHE_DELETE_QUEUE, cacheKey);
}
} catch (Exception e) {
log.error("删除缓存异常,发送到消息队列进行补偿,key: {}", cacheKey, e);
// 发送到消息队列进行补偿
rabbitTemplate.convertAndSend(CACHE_DELETE_QUEUE, cacheKey);
}
}
/**
* 消息队列消费者 - 处理缓存删除补偿
*/
@RabbitListener(queues = CACHE_DELETE_QUEUE)
public void handleCacheDeleteCompensation(String cacheKey) {
try {
redisTemplate.delete(cacheKey);
log.info("补偿删除缓存成功,key: {}", cacheKey);
} catch (Exception e) {
log.error("补偿删除缓存失败,key: {}", cacheKey, e);
// 可以设置重试次数限制
}
}
}
- 结论
这种方式最大的优点是可靠性高,可以结合事务消息来保证「数据库更新成功了,消息一定会发出去」。缺点是系统复杂度高了一些。
5. 采用读写分离的架构怎么办?
如果数据库采用的是读写分离的架构,那么又会出现新的问题,如下图:
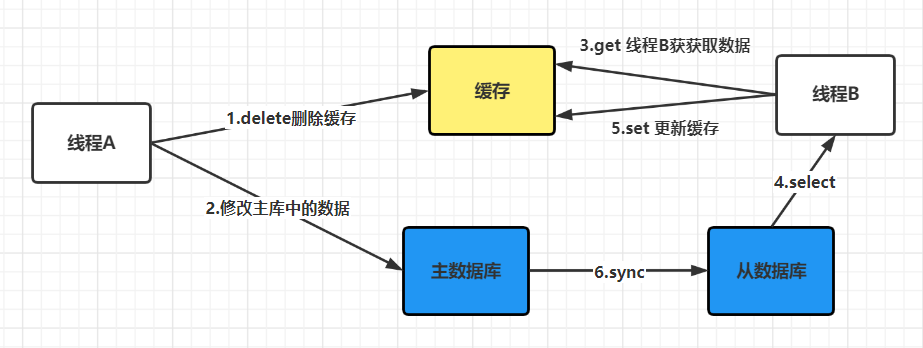
此时来了两个请求,请求 A(更新操作) 和请求 B(查询操作)
- 请求 A 更新操作,删除了 Redis;
- 请求主库进⾏更新操作,主库与从库进行同步数据的操作;
- 请 B 查询操作,发现 Redis 中没有数据;
- 去从库中拿去数据;
- 此时同步数据还未完成,拿到的数据是旧数据;
此时的解决办法就是如果是对 Redis 进行填充数据的查询数据库操作,那么就强制将其指向主库进⾏查询。
- 代码示例
@Service
public class UserService {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
@Autowired
private UserMapper userMapper;
@Autowired
private DataSource masterDataSource;
@Autowired
private DataSource slaveDataSource;
private static final String USER_CACHE_PREFIX = "user:";
private static final int MAX_RETRY_TIMES = 3;
/**
* 读写分离架构下的缓存更新策略
*/
public void updateUserWithReadWriteSeparation(User user) {
String cacheKey = USER_CACHE_PREFIX + user.getId();
try {
//1. 更新主库
userMapper.updateById(user);
// 2. 先删除缓存
redisTemplate.delete(cacheKey);
// 3. 延时删除缓存(防止主从同步延迟)
scheduleDelayedCacheDelete(cacheKey);
} catch (Exception e) {
log.error("更新用户失败,用户ID: {}", user.getId(), e);
throw new RuntimeException("更新用户失败", e);
}
}
/**
* 查询用户信息 - 处理主从延迟问题
*/
public User getUserById(Long userId) {
String cacheKey = USER_CACHE_PREFIX + userId;
// 1. 先从缓存获取
User user = (User) redisTemplate.opsForValue().get(cacheKey);
if (user != null) {
return user;
}
// 2. 缓存不存在,从主库查询(避免主从延迟)
user = userMapper.selectByIdFromMaster(userId);
if (user != null) {
// 3. 更新缓存
redisTemplate.opsForValue().set(cacheKey, user, Duration.ofMinutes(30));
}
return user;
}
/**
* 延时删除缓存
*/
private void scheduleDelayedCacheDelete(String cacheKey) {
CompletableFuture.runAsync(() -> {
try {
Thread.sleep(1000); // 延时1秒,等待主从同步
redisTemplate.delete(cacheKey);
log.info("延时删除缓存成功,key: {}", cacheKey);
} catch (Exception e) {
log.error("延时删除缓存失败,key: {}", cacheKey, e);
}
});
}
/**
* 带重试机制的缓存删除
*/
public void deleteCacheWithRetry(String cacheKey) {
int retryCount = 0;
boolean success = false;
while (retryCount < MAX_RETRY_TIMES && !success) {
try {
Boolean deleted = redisTemplate.delete(cacheKey);
if (deleted) {
success = true;
log.info("缓存删除成功,key: {}", cacheKey);
} else {
retryCount++;
log.warn("缓存删除失败,重试第{}次,key: {}", retryCount, cacheKey);
Thread.sleep(1000 * retryCount); // 递增延时
}
} catch (Exception e) {
retryCount++;
log.error("缓存删除异常,重试第{}次,key: {}", retryCount, cacheKey, e);
if (retryCount >= MAX_RETRY_TIMES) {
// 超出重试次数,记录日志并发送告警
log.error("缓存删除失败,已达到最大重试次数,key: {}", cacheKey);
sendAlert("缓存删除失败", "key: " + cacheKey);
}
}
}
}
/**
* 发送告警
*/
private void sendAlert(String subject, String message) {
// 实现告警逻辑,如发送邮件、短信等
log.error("告警: {} - {}", subject, message);
}
}
- 结论
在读写分离架构下,缓存一致性问题变得更加复杂,主要挑战包括:
主从延迟问题:从库数据更新存在延迟,可能导致读取到旧数据
解决方案:
- 对于缓存填充操作,强制从主库读取数据
- 采用延时双删策略,等待主从同步完成
- 实现重试机制,确保缓存删除的可靠性
最佳实践:
- 设置合理的重试次数和延时时间
- 建立完善的监控和告警机制
- 在业务允许的情况下,适当容忍短暂的数据不一致
注意事项:
- 延时时间需要根据主从同步的实际延迟来调整
- 重试机制要设置上限,避免无限重试
- 需要监控主从延迟情况,及时调整策略