
HashMap 底层原理深度解析
1. 引言
HashMap 是 Java 集合框架中最重要、最常用的数据结构之一。它提供了高效的键值对存储和检索功能,在 SpringBoot 应用开发中几乎无处不在。深入理解 HashMap 的底层实现原理,对于编写高性能、高质量的 Java 应用程序至关重要。
2. HashMap 概述
2.1 基本概念
HashMap 是基于哈希表实现的 Map 接口的非同步实现。它允许 null 键和 null 值,不保证映射的顺序,特别是它不保证该顺序恒久不变。
核心特点:
- 基于哈希表实现,提供 O(1) 的平均时间复杂度
- 非线程安全,多线程环境下需要使用 ConcurrentHashMap
- 允许 null 键和 null 值
- 不保证元素的顺序
2.2 HashMap 在集合框架中的位置
3. HashMap 的数据结构
3.1 JDK 1.8 之前:数组 + 链表
在 JDK 1.8 之前,HashMap 采用数组 + 链表的数据结构:
3.2 JDK 1.8 之后:数组 + 链表 + 红黑树
JDK 1.8 引入了红黑树优化,当链表长度超过 8 时,链表会转换为红黑树:
3.3 核心字段解析
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
// 默认初始容量:16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
// 最大容量:2^30
static final int MAXIMUM_CAPACITY = 1 << 30;
// 默认负载因子:0.75
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 链表转红黑树的阈值:8
static final int TREEIFY_THRESHOLD = 8;
// 红黑树转链表的阈值:6
static final int UNTREEIFY_THRESHOLD = 6;
// 最小树化容量:64
static final int MIN_TREEIFY_CAPACITY = 64;
// 存储元素的数组
transient Node<K,V>[] table;
// 键值对数量
transient int size;
// 修改次数(用于快速失败机制)
transient int modCount;
// 扩容阈值 = 容量 * 负载因子
int threshold;
// 负载因子
final float loadFactor;
}
3.4 Node 节点结构
// 链表节点
static class Node<K,V> implements Map.Entry<K,V> {
final int hash; // 哈希值
final K key; // 键
V value; // 值
Node<K,V> next; // 下一个节点
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
}
// 红黑树节点(继承自 LinkedHashMap.Entry)
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // 父节点
TreeNode<K,V> left; // 左子节点
TreeNode<K,V> right; // 右子节点
TreeNode<K,V> prev; // 前一个节点
boolean red; // 颜色标记
}
4. HashMap 的哈希算法
4.1 哈希值计算
HashMap 使用 key 的 hashCode() 方法计算哈希值,然后通过扰动函数进一步处理:
static final int hash(Object key) {
int h;
// key为null时,哈希值为0
// 否则:h = key.hashCode(),然后进行扰动处理
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
扰动函数的作用:
- 将 hashCode 的高 16 位与低 16 位进行异或运算
- 增加哈希值的随机性,减少哈希冲突
- 充分利用 hashCode 的所有位
4.2 数组索引计算
// 计算数组索引:index = (n - 1) & hash
// n 是数组长度(必须是2的幂)
int index = (table.length - 1) & hash;
为什么使用 (n - 1) & hash 而不是 hash % n?
- 位运算比取模运算效率更高
- 当 n 是 2 的幂时,
(n - 1) & hash等价于hash % n - 保证索引在有效范围内
4.3 哈希算法流程图
5. HashMap 的插入流程
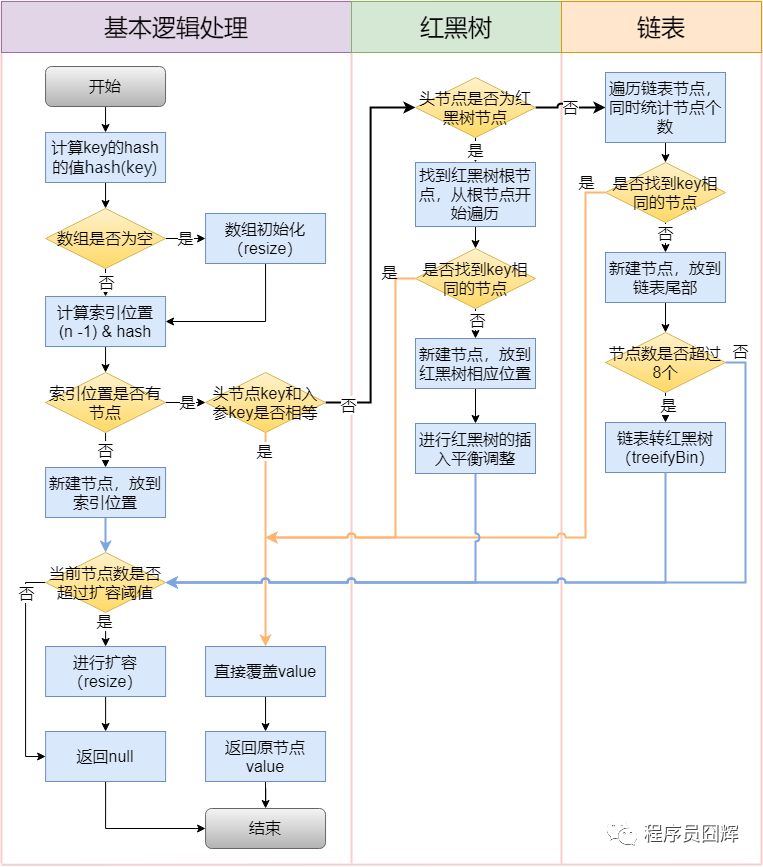
5.1 put() 方法核心流程
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 1. 如果数组为空或长度为0,进行扩容
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 2. 计算索引位置,如果该位置为空,直接插入
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
// 3. 如果key已存在,更新value
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 4. 如果是红黑树节点,调用红黑树的插入方法
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// 5. 如果是链表,遍历链表
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
// 在链表末尾插入新节点
p.next = newNode(hash, key, value, null);
// 如果链表长度 >= 8,转换为红黑树
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
break;
}
// 如果找到相同的key,更新value
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// 6. 更新已存在的key的value
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
// 7. 增加修改次数
++modCount;
// 8. 如果元素数量超过阈值,进行扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
5.2 插入流程示意图
6. HashMap 的扩容机制
6.1 扩容触发条件
HashMap 在以下情况下会进行扩容:
- 初始化时:第一次 put 元素时,如果数组为空,会进行初始化扩容
- 元素数量超过阈值:当
size > threshold时触发扩容threshold = capacity * loadFactor- 默认:
threshold = 16 * 0.75 = 12
6.2 resize() 方法核心逻辑
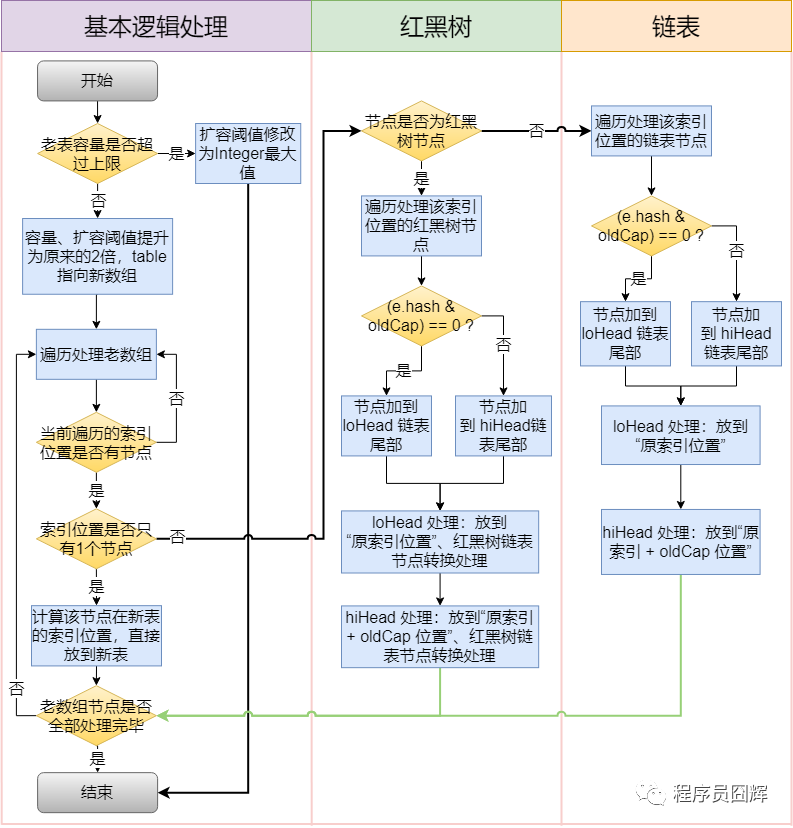
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
// 1. 计算新容量和新阈值
if (oldCap > 0) {
// 如果旧容量已经达到最大值,不再扩容
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 新容量 = 旧容量 * 2
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // 新阈值 = 旧阈值 * 2
}
else if (oldThr > 0) // 初始化时指定了容量
newCap = oldThr;
else { // 使用默认值
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : Integer.MAX_VALUE;
}
threshold = newThr;
// 2. 创建新数组
Node<K,V>[] newTab = (Node<K,V>[])(new Node[newCap]);
table = newTab;
// 3. 将旧数组中的元素重新分配到新数组
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
// 如果只有一个节点,直接重新计算索引
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
// 如果是红黑树,调用split方法
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
// 如果是链表,进行链表拆分
else {
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
// 根据(e.hash & oldCap)是否为0,将链表分为两部分
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
6.3 扩容机制详解
扩容特点:
- 容量总是 2 的幂次方(16 → 32 → 64 → 128...)
- 扩容时,元素重新计算索引位置
- JDK 1.8 优化:链表拆分时,元素要么在原位置,要么在原位置 + 旧容量
扩容优化原理:
// 旧容量 = 16,新容量 = 32
// 旧索引计算:index = hash & (16 - 1) = hash & 15
// 新索引计算:index = hash & (32 - 1) = hash & 31
// 判断元素在新数组中的位置:
// 如果 (hash & oldCap) == 0,元素在新数组中的位置 = 原位置
// 如果 (hash & oldCap) != 0,元素在新数组中的位置 = 原位置 + oldCap
6.4 扩容流程图
7. 链表转红黑树
7.1 树化条件
链表转换为红黑树需要满足两个条件:
- 链表长度 >= 8(TREEIFY_THRESHOLD)
- 数组长度 >= 64(MIN_TREEIFY_CAPACITY)
如果只满足条件1但不满足条件2,会先进行扩容而不是树化。
7.2 树化过程
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
// 如果数组长度 < 64,先扩容而不是树化
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
TreeNode<K,V> hd = null, tl = null;
// 将链表节点转换为树节点
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
// 将树节点构建成红黑树
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
7.3 为什么选择 8 作为阈值?
统计依据:
- 在理想情况下(哈希函数分布均匀),链表长度达到 8 的概率约为 0.00000006
- 红黑树的平均查找长度为 log(n),链表的平均查找长度为 n/2
- 当 n = 8 时,log(8) = 3 < 8/2 = 4,红黑树性能更好
性能对比:
8. HashMap 的查找流程
8.1 get() 方法
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
// 1. 数组不为空且长度>0,且索引位置有元素
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// 2. 检查第一个节点
if (first.hash == hash &&
((k = first.key) == key || (key != null && key.equals(k))))
return first;
// 3. 如果第一个节点不匹配,继续查找
if ((e = first.next) != null) {
// 4. 如果是红黑树,调用树查找
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
// 5. 如果是链表,遍历链表
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
8.2 查找流程示意图
9. SpringBoot 中的 HashMap 应用
9.1 缓存实现
在 SpringBoot 中,可以使用 HashMap 实现简单的本地缓存:
package com.example.demo.cache;
import org.springframework.stereotype.Component;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.locks.ReentrantReadWriteLock;
/**
* 基于HashMap的本地缓存实现
*/
@Component
public class LocalCache<K, V> {
private final Map<K, V> cache = new HashMap<>(16);
private final ReentrantReadWriteLock lock = new ReentrantReadWriteLock();
/**
* 获取缓存
*/
public V get(K key) {
lock.readLock().lock();
try {
return cache.get(key);
} finally {
lock.readLock().unlock();
}
}
/**
* 放入缓存
*/
public void put(K key, V value) {
lock.writeLock().lock();
try {
cache.put(key, value);
} finally {
lock.writeLock().unlock();
}
}
/**
* 移除缓存
*/
public V remove(K key) {
lock.writeLock().lock();
try {
return cache.remove(key);
} finally {
lock.writeLock().unlock();
}
}
/**
* 清空缓存
*/
public void clear() {
lock.writeLock().lock();
try {
cache.clear();
} finally {
lock.writeLock().unlock();
}
}
/**
* 获取缓存大小
*/
public int size() {
lock.readLock().lock();
try {
return cache.size();
} finally {
lock.readLock().unlock();
}
}
}
9.2 配置管理
使用 HashMap 存储应用配置:
package com.example.demo.config;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
import java.util.HashMap;
import java.util.Map;
/**
* 动态配置管理器
*/
@Component
public class DynamicConfigManager {
private final Map<String, Object> configMap = new HashMap<>(32);
@PostConstruct
public void init() {
// 初始化配置
configMap.put("app.name", "MyApplication");
configMap.put("app.version", "1.0.0");
configMap.put("cache.enabled", true);
configMap.put("cache.size", 1000);
}
/**
* 获取配置
*/
public <T> T getConfig(String key, Class<T> type) {
Object value = configMap.get(key);
return type.cast(value);
}
/**
* 设置配置
*/
public void setConfig(String key, Object value) {
configMap.put(key, value);
}
/**
* 获取所有配置
*/
public Map<String, Object> getAllConfigs() {
return new HashMap<>(configMap);
}
}
9.3 数据分组统计
使用 HashMap 进行数据分组和统计:
package com.example.demo.service;
import org.springframework.stereotype.Service;
import java.util.*;
import java.util.stream.Collectors;
@Service
public class OrderStatisticsService {
/**
* 按用户分组统计订单数量
*/
public Map<Long, Long> countOrdersByUser(List<Order> orders) {
// 使用HashMap进行分组统计
Map<Long, Long> userOrderCount = new HashMap<>();
for (Order order : orders) {
Long userId = order.getUserId();
userOrderCount.put(userId,
userOrderCount.getOrDefault(userId, 0L) + 1);
}
return userOrderCount;
}
/**
* 使用Stream API进行分组统计(更优雅的方式)
*/
public Map<Long, Long> countOrdersByUserStream(List<Order> orders) {
return orders.stream()
.collect(Collectors.groupingBy(
Order::getUserId,
Collectors.counting()
));
}
/**
* 按状态分组订单
*/
public Map<String, List<Order>> groupOrdersByStatus(List<Order> orders) {
Map<String, List<Order>> statusMap = new HashMap<>();
for (Order order : orders) {
String status = order.getStatus();
statusMap.computeIfAbsent(status, k -> new ArrayList<>())
.add(order);
}
return statusMap;
}
}
9.4 路由映射
在 SpringBoot 中,可以使用 HashMap 实现简单的路由映射:
package com.example.demo.router;
import org.springframework.stereotype.Component;
import java.util.HashMap;
import java.util.Map;
import java.util.function.Function;
/**
* 基于HashMap的路由器
*/
@Component
public class SimpleRouter {
private final Map<String, Function<Object, Object>> routes = new HashMap<>();
/**
* 注册路由
*/
public void register(String path, Function<Object, Object> handler) {
routes.put(path, handler);
}
/**
* 路由请求
*/
public Object route(String path, Object request) {
Function<Object, Object> handler = routes.get(path);
if (handler != null) {
return handler.apply(request);
}
throw new IllegalArgumentException("Route not found: " + path);
}
/**
* 检查路由是否存在
*/
public boolean hasRoute(String path) {
return routes.containsKey(path);
}
}
10. HashMap 的性能优化
10.1 合理设置初始容量
// ❌ 不好:频繁扩容
Map<String, Object> map = new HashMap<>();
for (int i = 0; i < 1000; i++) {
map.put("key" + i, "value" + i);
}
// ✅ 好:预估容量,避免扩容
// 预估1000个元素,考虑负载因子0.75,初始容量 = 1000 / 0.75 ≈ 1333
// 向上取最近的2的幂:2048
Map<String, Object> map = new HashMap<>(2048);
for (int i = 0; i < 1000; i++) {
map.put("key" + i, "value" + i);
}
10.2 选择合适的负载因子
// 默认负载因子0.75,适合大多数场景
Map<String, Object> map1 = new HashMap<>();
// 如果内存充足,可以降低负载因子,减少哈希冲突
// 负载因子越小,空间利用率越低,但查找性能越好
Map<String, Object> map2 = new HashMap<>(16, 0.5f);
// 如果内存紧张,可以增大负载因子,提高空间利用率
// 负载因子越大,空间利用率越高,但查找性能可能下降
Map<String, Object> map3 = new HashMap<>(16, 0.9f);
10.3 重写 hashCode() 和 equals()
public class User {
private Long id;
private String name;
private String email;
// ✅ 正确实现equals和hashCode
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
User user = (User) o;
return Objects.equals(id, user.id) &&
Objects.equals(name, user.name) &&
Objects.equals(email, user.email);
}
@Override
public int hashCode() {
return Objects.hash(id, name, email);
}
// ❌ 错误:只重写equals,不重写hashCode
// 这会导致HashMap无法正确工作
}
10.4 使用合适的键类型
// ✅ 好的键类型:String、Integer等不可变类型
Map<String, Object> map1 = new HashMap<>();
Map<Integer, Object> map2 = new HashMap<>();
// ⚠️ 注意:使用自定义对象作为键时,确保不可变
public final class UserKey {
private final Long id;
private final String type;
public UserKey(Long id, String type) {
this.id = id;
this.type = type;
}
// getter方法...
// equals和hashCode方法...
}
11. HashMap 的线程安全问题
11.1 为什么 HashMap 不是线程安全的?
HashMap 在并发环境下可能出现以下问题:
- 数据丢失:多个线程同时 put,可能覆盖数据
- 死循环:JDK 1.7 及之前版本,并发扩容可能导致死循环
- 数据不一致:读取和写入同时进行,可能读到不一致的数据
11.2 线程安全的替代方案
// 1. 使用 ConcurrentHashMap(推荐)
Map<String, Object> map1 = new ConcurrentHashMap<>();
// 2. 使用 Collections.synchronizedMap(性能较差)
Map<String, Object> map2 = Collections.synchronizedMap(new HashMap<>());
// 3. 使用 Hashtable(不推荐,性能差)
Map<String, Object> map3 = new Hashtable<>();
11.3 SpringBoot 中的线程安全实践
package com.example.demo.service;
import org.springframework.stereotype.Service;
import java.util.concurrent.ConcurrentHashMap;
import java.util.Map;
@Service
public class ThreadSafeCacheService {
// 使用ConcurrentHashMap保证线程安全
private final Map<String, Object> cache = new ConcurrentHashMap<>();
/**
* 线程安全的缓存操作
*/
public void put(String key, Object value) {
cache.put(key, value);
}
public Object get(String key) {
return cache.get(key);
}
/**
* 使用computeIfAbsent实现线程安全的懒加载
*/
public Object getOrCompute(String key,
java.util.function.Function<String, Object> supplier) {
return cache.computeIfAbsent(key, supplier);
}
}
12. HashMap vs 其他 Map 实现
12.1 对比表格
| 特性 | HashMap | LinkedHashMap | TreeMap | ConcurrentHashMap | Hashtable |
|---|---|---|---|---|---|
| 底层实现 | 数组+链表+红黑树 | HashMap+双向链表 | 红黑树 | 分段锁/CAS | 数组+链表 |
| 有序性 | 无序 | 插入顺序 | 自然顺序 | 无序 | 无序 |
| null键值 | 允许 | 允许 | 不允许 | 不允许 | 不允许 |
| 线程安全 | 否 | 否 | 否 | 是 | 是 |
| 性能 | O(1) | O(1) | O(log n) | O(1) | O(1) |
| 使用场景 | 快速查找 | 保持插入顺序 | 有序存储 | 并发环境 | 不推荐使用 |
12.2 选择建议
13. 常见问题与解答
13.1 为什么 HashMap 的容量必须是 2 的幂?
原因:
- 位运算优化:
(n - 1) & hash比hash % n效率更高 - 均匀分布:2 的幂可以保证哈希值均匀分布
- 扩容优化:扩容时可以利用位运算快速判断元素新位置
13.2 负载因子为什么是 0.75?
原因:
- 空间与时间的平衡:0.75 是经过大量实验得出的最佳平衡点
- 数学依据:在泊松分布下,0.75 的负载因子可以最小化哈希冲突
- 实际效果:既不会浪费太多空间,也不会导致过多的哈希冲突
13.3 HashMap 在 JDK 1.8 做了哪些优化?
- 引入红黑树:链表长度超过 8 时转换为红黑树,提高查找效率
- 优化扩容:扩容时元素位置要么不变,要么是原位置+旧容量
- 优化哈希算法:改进了扰动函数,减少哈希冲突
- 优化插入逻辑:使用尾插法代替头插法,避免并发扩容时的死循环
13.4 如何避免 HashMap 的哈希冲突?
- 良好的 hashCode 实现:确保不同的对象有不同的哈希值
- 合理的初始容量:避免频繁扩容
- 合适的负载因子:根据实际情况调整
- 使用不可变对象作为键:避免键的变化导致哈希值变化
14. 总结
HashMap 是 Java 集合框架中最重要的数据结构之一,深入理解其底层原理对于编写高性能的 Java 应用程序至关重要。
核心要点:
- 数据结构:数组 + 链表 + 红黑树(JDK 1.8+)
- 哈希算法:通过扰动函数减少冲突
- 扩容机制:容量翻倍,元素重新分布
- 性能优化:合理设置初始容量和负载因子
- 线程安全:多线程环境使用 ConcurrentHashMap
在 SpringBoot 中的应用:
- 本地缓存实现
- 配置管理
- 数据分组统计
- 路由映射
掌握 HashMap 的底层原理,可以帮助我们:
- 编写更高效的代码
- 避免常见的性能问题
- 正确使用 HashMap 及其相关类
- 在面试中脱颖而出