
YOLO11 深度学习目标检测框架
什么是 YOLO11?
YOLO11(You Only Look Once v11)是 Ultralytics 公司开发的最新一代实时目标检测算法,代表了计算机视觉领域的最新突破。作为 YOLO 系列的最新版本,YOLO11 在速度、精度和功能多样性方面都实现了显著提升。
想象一下,你需要在视频中实时识别和定位各种物体,比如行人、车辆、动物等。YOLO11 就像一个"超级视觉助手",能够在毫秒级时间内完成这些复杂的识别任务,而且准确率极高。无论是自动驾驶、安防监控,还是医疗影像分析,YOLO11 都能提供强大的技术支持。
为什么选择 YOLO11?
1. 技术优势
YOLO11 相比其他目标检测算法具有显著优势:
2. 应用场景
YOLO11 广泛应用于各个领域:
3. 技术特点
实时性能优势:
- 单次前向传播:一次网络推理完成所有检测任务
- 毫秒级响应:在 GPU 上可达到 30+ FPS
- 低延迟:适合实时应用场景
- 高效推理:优化的网络结构减少计算量
高精度检测:
- SOTA 性能:在 COCO 数据集上达到最佳性能
- 多尺度检测:能够检测不同大小的目标
- 小目标优化:特别针对小目标检测进行优化
- 边界框精确:提供高精度的目标定位
多功能支持:
- 一体化框架:检测、分割、分类、姿态估计统一
- 任务切换:同一模型支持多种任务
- 灵活配置:可根据需求选择不同功能
- 模块化设计:易于扩展和定制
YOLO11 技术架构
1. 整体架构图
2. 核心组件详解
骨干网络 (Backbone):
- C2f 模块:改进的 CSP 结构,增强特征融合
- 多尺度特征:提取不同层次的特征信息
- 轻量化设计:在保持精度的同时减少参数量
颈部网络 (Neck):
- FPN:特征金字塔网络,融合多尺度特征
- PAN:路径聚合网络,增强特征传递
- 双向融合:自顶向下和自底向上的特征融合
检测头 (Head):
- 解耦设计:检测、分类、分割头独立设计
- 多任务学习:同时优化多个任务目标
- 动态权重:根据任务重要性调整损失权重
模型系列对比
1. 检测模型性能对比
YOLO11 提供 5 个不同规模的检测模型,满足不同应用需求:
| 模型 | 参数量(M) | FLOPs(B) | mAP@0.5:0.95 | 速度(ms) | 适用场景 |
|---|---|---|---|---|---|
| YOLO11n | 2.6 | 6.5 | 39.5 | 1.5 | 移动端、边缘设备 |
| YOLO11s | 9.4 | 21.5 | 47.0 | 2.5 | 实时应用 |
| YOLO11m | 20.1 | 68.0 | 51.5 | 4.7 | 平衡性能 |
| YOLO11l | 25.3 | 86.9 | 53.4 | 6.2 | 高精度需求 |
| YOLO11x | 56.9 | 194.9 | 54.7 | 11.3 | 研究实验 |
性能分析:
2. 任务类型对比
目标检测 (Object Detection):
- 定义:计算机视觉任务,识别图像中目标的位置和类别
- 输出:边界框坐标 (x, y, w, h) + 类别标签 + 置信度分数
- 应用:自动驾驶、安防监控、医疗影像等
实例分割 (Instance Segmentation):
- 定义:在目标检测基础上,为每个目标生成像素级掩码
- 输出:边界框 + 类别 + 像素级掩码
- 应用:医学影像分析、自动驾驶场景理解
图像分类 (Image Classification):
- 定义:将整张图像分类到预定义的类别中
- 输出:类别标签 + 置信度分数
- 应用:内容审核、图像检索、质量控制
姿态估计 (Pose Estimation):
- 定义:检测人体关键点位置,构建骨骼结构
- 输出:关键点坐标 + 置信度分数
- 应用:动作识别、运动分析、人机交互
模型系列
检测模型(Detection)
YOLO11 提供 5 个不同规模的检测模型,满足不同应用需求:
| 模型 | 参数量(M) | FLOPs(B) | mAP@0.5:0.95 | 速度(ms) | 适用场景 |
|---|---|---|---|---|---|
| YOLO11n | 2.6 | 6.5 | 39.5 | 1.5 | 移动端、边缘设备 |
| YOLO11s | 9.4 | 21.5 | 47.0 | 2.5 | 实时应用 |
| YOLO11m | 20.1 | 68.0 | 51.5 | 4.7 | 平衡性能 |
| YOLO11l | 25.3 | 86.9 | 53.4 | 6.2 | 高精度需求 |
| YOLO11x | 56.9 | 194.9 | 54.7 | 11.3 | 研究实验 |
目标检测 (Object Detection)
- 定义:计算机视觉任务,识别图像中目标的位置和类别
- 输出:边界框坐标 (x, y, w, h) + 类别标签 + 置信度分数
- 应用:自动驾驶、安防监控、医疗影像等
分割模型(Segmentation)
实例分割模型能够精确分割目标轮廓:
| 模型 | mAP@0.5:0.95 | mAP_mask | 速度(ms) | 应用场景 |
|---|---|---|---|---|
| YOLO11n-seg | 38.9 | 32.0 | 1.8 | 轻量级分割 |
| YOLO11s-seg | 46.6 | 37.8 | 2.9 | 实时分割 |
| YOLO11m-seg | 51.5 | 41.5 | 6.3 | 高精度分割 |
| YOLO11l-seg | 53.4 | 42.9 | 7.8 | 研究级分割 |
| YOLO11x-seg | 54.7 | 43.8 | 15.8 | 最高精度 |
实例分割 (Instance Segmentation)
- 定义:在目标检测基础上,为每个目标生成像素级掩码
- 输出:边界框 + 类别 + 像素级掩码
- 应用:医学影像分析、自动驾驶场景理解
分类模型(Classification)
图像分类模型用于整图分类任务:
| 模型 | Top-1 Acc | Top-5 Acc | 速度(ms) | 应用场景 |
|---|---|---|---|---|
| YOLO11n-cls | 70.0% | 89.4% | 1.1 | 轻量级分类 |
| YOLO11s-cls | 75.4% | 92.7% | 1.3 | 实时分类 |
| YOLO11m-cls | 77.3% | 93.9% | 2.0 | 高精度分类 |
| YOLO11l-cls | 78.3% | 94.3% | 2.8 | 研究级分类 |
| YOLO11x-cls | 79.5% | 94.9% | 3.8 | 最高精度 |
图像分类 (Image Classification)
- 定义:将整张图像分类到预定义的类别中
- 输出:类别标签 + 置信度分数
- 应用:内容审核、图像检索、质量控制
姿态模型(Pose Estimation)
人体姿态估计模型用于关键点检测:
| 模型 | mAP_pose@0.5:0.95 | mAP_pose@0.5 | 速度(ms) | 应用场景 |
|---|---|---|---|---|
| YOLO11n-pose | 78.4 | 117.6 | 4.4 | 轻量级姿态 |
| YOLO11s-pose | 79.5 | 219.4 | 5.1 | 实时姿态 |
| YOLO11m-pose | 80.9 | 562.8 | 10.1 | 高精度姿态 |
| YOLO11l-pose | 81.0 | 712.5 | 13.5 | 研究级姿态 |
| YOLO11x-pose | 81.3 | 1408.6 | 28.6 | 最高精度 |
姿态估计 (Pose Estimation)
- 定义:检测人体关键点位置,构建骨骼结构
- 输出:关键点坐标 + 置信度分数
- 应用:动作识别、运动分析、人机交互
环境安装与配置
1. 系统要求
硬件要求:
- CPU:支持 AVX 指令集的现代处理器
- 内存:至少 8GB RAM,推荐 16GB 以上
- 存储:至少 5GB 可用空间
- GPU(推荐):NVIDIA GPU,支持 CUDA 11.0+
软件要求:
- Python:3.8-3.12(推荐 3.10)
- 操作系统:Windows 10+, macOS 10.15+, Ubuntu 18.04+
- CUDA(GPU 版本):11.0-12.4
- cuDNN(GPU 版本):8.0-8.9
2. 安装流程
环境准备
- 创建 conda 虚拟环境
conda create --name yolo pyhton=3.10
- 激活环境
conda activate yolo
- 安装 pytorch
查看系统 CUDA 版本,pytorch 版本需要与 CUDA 版本兼容
nvcc -V
我的 CUDA 版本是: 12.4,然后去pytorch 官网获取对应的版本链接
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124
至此 yolo 项目前期准备就完成了
源码安装
git clone https://github.com/ultralytics/ultralytics.git
安装 ultralytics
cmd 进入 ultralytics 项目
激活 yolo 环境
conda activate yolo
3.安装requirements.txt
如果项目中没有,手动创建后复制以下内容:
certifi==2022.12.7
charset-normalizer==2.1.1
colorama==0.4.6
contourpy==1.2.0
cycler==0.12.1
filelock==3.9.0
fonttools==4.50.0
fsspec==2024.6.1
huggingface-hub==0.23.4
idna==3.4
Jinja2==3.1.2
kiwisolver==1.4.5
MarkupSafe==2.1.3
matplotlib==3.8.3
mpmath==1.3.0
networkx==3.2.1
numpy==1.26.3
opencv-python==4.9.0.80
packaging==24.0
pandas==2.2.1
pillow==10.2.0
psutil==5.9.8
py-cpuinfo==9.0.0
pyparsing==3.1.2
python-dateutil==2.9.0.post0
pytz==2024.1
PyYAML==6.0.1
requests==2.28.1
scipy==1.12.0
seaborn==0.13.2
six==1.16.0
sympy==1.12
thop==0.1.1.post2209072238
tqdm==4.66.2
typing_extensions==4.8.0
tzdata==2024.1
ultralytics==8.1.34
urllib3==1.26.13
这里要注意:我们之前已经根据系统 cuda 安装过pytorch,所以要把文件中的torch注释掉,下面开始安装:
pip install -r requirements.txt
至此 yolo 就安装好了
pip 安装 ultralytics(源码安装和 pip 安装二选一)
- 也是激活环境
conda activate yolo
- 安装
pip install ultralytics
- ultralytics 安装结束
数据准备与标注
1. 数据集结构设计
YOLO11 需要特定的数据集结构来确保训练和验证的顺利进行:
标准数据集结构:
dataset/
├── train/
│ ├── images/
│ │ ├── img1.jpg
│ │ ├── img2.jpg
│ │ └── ...
│ └── labels/
│ ├── img1.txt
│ ├── img2.txt
│ └── ...
├── val/
│ ├── images/
│ │ ├── img100.jpg
│ │ ├── img101.jpg
│ │ └── ...
│ └── labels/
│ ├── img100.txt
│ ├── img101.txt
│ └── ...
├── test/
│ ├── images/
│ │ └── ...
│ └── labels/
│ └── ...
└── data.yaml
2. 数据标注格式
YOLO 格式标注:
每个图像对应一个同名的 .txt 文件,格式为:
class_id center_x center_y width height
标注示例:
# 示例:img1.txt
0 0.5 0.3 0.2 0.4 # 类别0,中心点(0.5,0.3),宽0.2,高0.4
1 0.8 0.6 0.15 0.3 # 类别1,中心点(0.8,0.6),宽0.15,高0.3
2 0.2 0.7 0.1 0.2 # 类别2,中心点(0.2,0.7),宽0.1,高0.2
坐标说明:
- 所有坐标都是归一化的(0-1 之间)
center_x, center_y:边界框中心点坐标width, height:边界框的宽度和高度class_id:类别 ID(从 0 开始)
3. 数据集配置文件
data.yaml 配置示例:
# data.yaml
path: ../datasets/coco # 数据集根目录
train: train/images # 训练图像路径
val: val/images # 验证图像路径
test: test/images # 测试图像路径(可选)
# 类别数量和名称
nc: 80 # 类别数量
names:
0: person
1: bicycle
2: car
3: motorcycle
4: airplane
5: bus
6: train
7: truck
8: boat
9: traffic light
10: fire hydrant
11: stop sign
12: parking meter
13: bench
14: bird
15: cat
16: dog
17: horse
18: sheep
19: cow
# ... 更多类别
配置文件详解:
| 参数 | 说明 | 示例 |
|---|---|---|
path | 数据集根目录路径 | ../datasets/coco |
train | 训练集图像路径 | train/images |
val | 验证集图像路径 | val/images |
test | 测试集图像路径(可选) | test/images |
nc | 类别数量 | 80 |
names | 类别名称映射 | 0: person, 1: bicycle |
4. 数据质量要求
图像质量:
- 分辨率:建议至少 416x416 像素
- 格式:支持 JPG、PNG、BMP 等常见格式
- 质量:图像清晰,无严重模糊或噪声
- 多样性:包含不同光照、角度、背景的图像
标注质量:
- 准确性:边界框准确框选目标
- 完整性:所有目标都被标注
- 一致性:同类目标使用相同的标注标准
- 平衡性:各类别样本数量相对平衡
数据分布:
5. 数据增强策略
基础增强:
# 数据增强配置
augment_config = {
'hsv_h': 0.015, # 色调变化
'hsv_s': 0.7, # 饱和度变化
'hsv_v': 0.4, # 亮度变化
'degrees': 0.0, # 旋转角度
'translate': 0.1, # 平移范围
'scale': 0.5, # 缩放范围
'shear': 0.0, # 剪切变换
'perspective': 0.0, # 透视变换
'flipud': 0.0, # 上下翻转
'fliplr': 0.5, # 左右翻转
'mosaic': 1.0, # 马赛克增强
'mixup': 0.0, # 混合增强
}
高级增强:
# 高级数据增强
advanced_augment = {
'erasing': 0.0, # 随机擦除
'auto_augment': None, # 自动增强
'grid_mask': 0.0, # 网格掩码
'copy_paste': 0.0, # 复制粘贴
}
6. 数据预处理工具
图像预处理:
import cv2
import numpy as np
from PIL import Image
def preprocess_image(image_path, target_size=(640, 640)):
"""图像预处理函数"""
# 读取图像
image = cv2.imread(image_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 调整大小
image = cv2.resize(image, target_size)
# 归一化
image = image.astype(np.float32) / 255.0
return image
def validate_annotation(annotation_path, image_shape):
"""验证标注文件"""
with open(annotation_path, 'r') as f:
lines = f.readlines()
for line in lines:
parts = line.strip().split()
if len(parts) != 5:
return False
class_id, x, y, w, h = map(float, parts)
# 检查坐标范围
if not (0 <= x <= 1 and 0 <= y <= 1 and 0 <= w <= 1 and 0 <= h <= 1):
return False
return True
数据集统计:
def analyze_dataset(data_yaml_path):
"""分析数据集统计信息"""
import yaml
import os
from collections import Counter
with open(data_yaml_path, 'r') as f:
config = yaml.safe_load(f)
# 统计各类别数量
class_counts = Counter()
total_images = 0
for split in ['train', 'val', 'test']:
if split in config:
images_dir = os.path.join(config['path'], config[split])
labels_dir = images_dir.replace('images', 'labels')
for img_file in os.listdir(images_dir):
if img_file.endswith(('.jpg', '.png', '.jpeg')):
total_images += 1
label_file = img_file.rsplit('.', 1)[0] + '.txt'
label_path = os.path.join(labels_dir, label_file)
if os.path.exists(label_path):
with open(label_path, 'r') as f:
for line in f:
class_id = int(line.split()[0])
class_counts[class_id] += 1
print(f"总图像数量: {total_images}")
print(f"类别分布: {dict(class_counts)}")
return class_counts
7. 常见数据问题
问题 1:标注格式错误
# 检查标注格式
def check_annotation_format(annotation_path):
"""检查标注文件格式"""
try:
with open(annotation_path, 'r') as f:
for line_num, line in enumerate(f, 1):
parts = line.strip().split()
if len(parts) != 5:
print(f"第{line_num}行格式错误: {line}")
return False
class_id, x, y, w, h = map(float, parts)
if not (0 <= x <= 1 and 0 <= y <= 1 and 0 <= w <= 1 and 0 <= h <= 1):
print(f"第{line_num}行坐标超出范围: {line}")
return False
except Exception as e:
print(f"读取文件错误: {e}")
return False
return True
问题 2:类别不平衡
# 处理类别不平衡
def balance_dataset(class_counts, target_count=1000):
"""平衡数据集"""
balanced_data = {}
for class_id, count in class_counts.items():
if count < target_count:
# 数据增强
balanced_data[class_id] = target_count
else:
# 随机采样
balanced_data[class_id] = target_count
return balanced_data
问题 3:图像质量问题
# 图像质量检查
def check_image_quality(image_path, min_size=416):
"""检查图像质量"""
image = cv2.imread(image_path)
if image is None:
return False, "无法读取图像"
h, w = image.shape[:2]
if h < min_size or w < min_size:
return False, f"图像尺寸过小: {w}x{h}"
# 检查图像是否模糊
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blur_score = cv2.Laplacian(gray, cv2.CV_64F).var()
if blur_score < 100:
return False, f"图像模糊: {blur_score}"
return True, "图像质量良好"
模型训练
1. 训练流程概览
2. 基础训练代码
创建训练脚本:
# train.py
from ultralytics import YOLO
import torch
def main():
# 检查设备
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(f"使用设备: {device}")
# 加载预训练模型
model = YOLO('yolov11n.pt') # 选择模型大小
# 开始训练
results = model.train(
data='data.yaml', # 数据集配置文件
epochs=100, # 训练轮数
imgsz=640, # 输入图像尺寸
batch=16, # 批次大小
device=device, # 设备选择
workers=8, # 数据加载线程数
project='runs/train', # 项目目录
name='exp', # 实验名称
save=True, # 保存模型
save_period=10, # 每10轮保存一次
patience=50, # 早停耐心值
verbose=True, # 详细输出
)
print("训练完成!")
return results
if __name__ == "__main__":
results = main()
模型选择指南:
| 模型 | 参数量 | 速度 | 精度 | 适用场景 |
|---|---|---|---|---|
| YOLO11n | 2.6M | 最快 | 中等 | 移动端、边缘设备 |
| YOLO11s | 9.4M | 快 | 良好 | 实时应用 |
| YOLO11m | 20.1M | 中等 | 很好 | 平衡性能 |
| YOLO11l | 25.3M | 较慢 | 优秀 | 高精度需求 |
| YOLO11x | 56.9M | 最慢 | 最佳 | 研究实验 |
3. 高级训练配置
完整训练参数:
# 高级训练配置
def advanced_training():
model = YOLO('yolov11m.pt')
# 训练参数
training_args = {
# 基础参数
'data': 'data.yaml',
'epochs': 200,
'imgsz': 640,
'batch': 16,
'device': 0,
'workers': 8,
# 项目设置
'project': 'runs/train',
'name': 'yolo11_experiment',
'exist_ok': True,
# 保存设置
'save': True,
'save_period': 10,
'save_last': True,
'save_best': True,
# 验证设置
'val': True,
'plots': True,
'save_json': False,
'save_hybrid': False,
# 早停设置
'patience': 50,
'close_mosaic': 10,
# 优化器参数
'lr0': 0.01,
'lrf': 0.01,
'momentum': 0.937,
'weight_decay': 0.0005,
'warmup_epochs': 3.0,
'warmup_momentum': 0.8,
'warmup_bias_lr': 0.1,
# 学习率调度
'cos_lr': False,
'scheduler': 'auto',
# 数据增强
'hsv_h': 0.015,
'hsv_s': 0.7,
'hsv_v': 0.4,
'degrees': 0.0,
'translate': 0.1,
'scale': 0.5,
'shear': 0.0,
'perspective': 0.0,
'flipud': 0.0,
'fliplr': 0.5,
'mosaic': 1.0,
'mixup': 0.0,
'copy_paste': 0.0,
# 损失函数权重
'box': 7.5,
'cls': 0.5,
'dfl': 1.5,
'pose': 12.0,
'kobj': 2.0,
'label_smoothing': 0.0,
# 模型架构
'anchors': 9,
'overlap_mask': True,
'mask_ratio': 4,
# 验证参数
'conf': 0.001,
'iou': 0.6,
'max_det': 300,
# 训练策略
'rect': False,
'multi_scale': False,
# 其他设置
'cache': False,
'amp': True,
'fraction': 1.0,
'profile': False,
'freeze': None,
'multi_scale': False,
'overlap_mask': True,
'mask_ratio': 4,
'dropout': 0.0,
'verbose': True,
}
# 开始训练
results = model.train(**training_args)
return results
4. 训练监控与可视化
实时监控:
# 训练监控
def monitor_training():
from ultralytics import YOLO
import matplotlib.pyplot as plt
# 加载模型
model = YOLO('yolov11m.pt')
# 开始训练
results = model.train(
data='data.yaml',
epochs=100,
imgsz=640,
batch=16,
device=0,
project='runs/train',
name='monitored_exp',
plots=True, # 生成训练图表
verbose=True,
)
# 绘制训练曲线
results.plot()
return results
自定义回调函数:
# 自定义训练回调
class TrainingCallback:
def __init__(self):
self.best_loss = float('inf')
self.epoch_losses = []
def on_train_epoch_end(self, trainer):
"""训练轮次结束回调"""
current_loss = trainer.loss.item()
self.epoch_losses.append(current_loss)
if current_loss < self.best_loss:
self.best_loss = current_loss
print(f"新的最佳损失: {current_loss:.4f}")
# 每10轮打印一次统计信息
if trainer.epoch % 10 == 0:
print(f"Epoch {trainer.epoch}: Loss = {current_loss:.4f}")
def on_val_end(self, trainer):
"""验证结束回调"""
val_loss = trainer.validator.loss.item()
print(f"验证损失: {val_loss:.4f}")
# 使用自定义回调
def training_with_callback():
model = YOLO('yolov11m.pt')
# 添加回调
callback = TrainingCallback()
results = model.train(
data='data.yaml',
epochs=100,
imgsz=640,
batch=16,
device=0,
project='runs/train',
name='callback_exp',
)
return results
5. 多 GPU 训练
分布式训练:
# 多GPU训练
def multi_gpu_training():
import torch
from ultralytics import YOLO
# 检查可用GPU
if torch.cuda.device_count() > 1:
print(f"发现 {torch.cuda.device_count()} 个GPU")
# 设置多GPU训练
model = YOLO('yolov11m.pt')
results = model.train(
data='data.yaml',
epochs=100,
imgsz=640,
batch=32, # 增加批次大小
device=[0, 1, 2, 3], # 使用多个GPU
workers=16, # 增加工作线程
project='runs/train',
name='multi_gpu_exp',
)
else:
print("只有一个GPU,使用单GPU训练")
model = YOLO('yolov11m.pt')
results = model.train(
data='data.yaml',
epochs=100,
imgsz=640,
batch=16,
device=0,
)
return results
6. 训练中断与恢复
断点续训:
# 断点续训
def resume_training():
model = YOLO('yolov11m.pt')
# 从断点恢复训练
results = model.train(
data='data.yaml',
epochs=100,
imgsz=640,
batch=16,
device=0,
project='runs/train',
name='resume_exp',
resume=True, # 恢复训练
)
return results
手动保存检查点:
# 手动保存检查点
def manual_checkpoint():
model = YOLO('yolov11m.pt')
for epoch in range(100):
# 训练一个epoch
results = model.train(
data='data.yaml',
epochs=1,
imgsz=640,
batch=16,
device=0,
project='runs/train',
name='manual_checkpoint',
)
# 每10个epoch保存一次
if epoch % 10 == 0:
model.save(f'checkpoint_epoch_{epoch}.pt')
print(f"保存检查点: checkpoint_epoch_{epoch}.pt")
7. 训练结果分析
结果可视化:
# 训练结果分析
def analyze_results(results):
import matplotlib.pyplot as plt
# 获取训练历史
metrics = results.results_dict
# 绘制损失曲线
plt.figure(figsize=(12, 8))
plt.subplot(2, 2, 1)
plt.plot(metrics['train/box_loss'], label='Train Box Loss')
plt.plot(metrics['val/box_loss'], label='Val Box Loss')
plt.title('Box Loss')
plt.legend()
plt.subplot(2, 2, 2)
plt.plot(metrics['train/cls_loss'], label='Train Cls Loss')
plt.plot(metrics['val/cls_loss'], label='Val Cls Loss')
plt.title('Classification Loss')
plt.legend()
plt.subplot(2, 2, 3)
plt.plot(metrics['metrics/precision(B)'], label='Precision')
plt.plot(metrics['metrics/recall(B)'], label='Recall')
plt.title('Precision & Recall')
plt.legend()
plt.subplot(2, 2, 4)
plt.plot(metrics['metrics/mAP50(B)'], label='mAP@0.5')
plt.plot(metrics['metrics/mAP50-95(B)'], label='mAP@0.5:0.95')
plt.title('mAP Metrics')
plt.legend()
plt.tight_layout()
plt.show()
return metrics
模型性能评估:
# 模型性能评估
def evaluate_model(model_path, data_yaml):
from ultralytics import YOLO
# 加载训练好的模型
model = YOLO(model_path)
# 在验证集上评估
results = model.val(
data=data_yaml,
imgsz=640,
batch=16,
device=0,
project='runs/val',
name='evaluation',
plots=True,
)
# 打印评估结果
print(f"mAP@0.5: {results.box.map50:.4f}")
print(f"mAP@0.5:0.95: {results.box.map:.4f}")
print(f"Precision: {results.box.mp:.4f}")
print(f"Recall: {results.box.mr:.4f}")
return results
训练参数详解
1. 参数分类概览
2. 基础训练参数
2.1 数据集相关参数
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
data | str | - | 数据集配置文件路径(YAML 格式) |
task | str | 'detect' | 任务类型:'detect', 'segment', 'classify', 'pose' |
mode | str | 'train' | 运行模式:'train', 'val', 'predict', 'export' |
参数详解:
# 数据集配置示例
data_config = {
'data': 'path/to/data.yaml', # 数据集配置文件
'task': 'detect', # 任务类型
'mode': 'train', # 运行模式
}
# 任务类型说明
task_types = {
'detect': '目标检测',
'segment': '实例分割',
'classify': '图像分类',
'pose': '姿态估计'
}
2.2 训练控制参数
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
epochs | int | 100 | 训练轮数,建议根据数据集大小调整 |
patience | int | 50 | 早停耐心值,连续多少轮无改善后停止训练 |
save | bool | True | 是否保存模型权重 |
save_period | int | -1 | 每 N 轮保存一次模型(-1 表示只保存最佳和最后) |
cache | bool | False | 是否缓存图像到内存中(小数据集推荐开启) |
参数调优建议:
# 根据数据集大小调整训练轮数
def get_epochs(dataset_size):
if dataset_size < 1000:
return 300
elif dataset_size < 10000:
return 200
else:
return 100
# 根据硬件配置调整缓存
def get_cache_config(gpu_memory_gb):
if gpu_memory_gb >= 16:
return True # 开启缓存
else:
return False # 关闭缓存
2.3 图像和批次参数
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
imgsz | int | 640 | 输入图像尺寸,必须是 32 的倍数 |
batch | int | 16 | 批次大小,根据 GPU 显存调整 |
workers | int | 8 | 数据加载线程数,建议为 CPU 核心数的 2-4 倍 |
批次大小选择指南:
# 根据GPU显存选择批次大小
def get_batch_size(gpu_memory_gb, model_size):
if gpu_memory_gb >= 24:
return 32
elif gpu_memory_gb >= 16:
return 16
elif gpu_memory_gb >= 8:
return 8
else:
return 4
# 根据模型大小调整图像尺寸
def get_image_size(model_name):
if 'n' in model_name: # nano
return 416
elif 's' in model_name: # small
return 512
else: # medium, large, xlarge
return 640
2.4 设备参数
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
device | str/int | 'auto' | 训练设备:'cpu', '0', '0,1', 'auto' |
amp | bool | True | 是否使用混合精度训练(节省显存) |
设备配置示例:
# 设备配置
device_configs = {
'cpu': 'cpu', # CPU训练
'single_gpu': 0, # 单GPU训练
'multi_gpu': [0, 1, 2, 3], # 多GPU训练
'auto': 'auto', # 自动选择
}
# 混合精度训练
amp_config = {
'amp': True, # 开启混合精度
'half': False, # 使用FP16
'dnn': False, # 使用OpenCV DNN
}
3. 优化器参数详解
3.1 学习率参数
| 参数 | 类型 | 默认值 | 说明 | 作用与影响 |
|---|---|---|---|---|
lr0 | float | 0.01 | 初始学习率 | 作用:控制模型参数更新的步长大小 影响:过大导致训练不稳定,过小导致收敛缓慢 调整建议:小数据集用 0.01,大数据集用 0.005 |
lrf | float | 0.01 | 最终学习率因子(lr0 * lrf) | 作用:控制学习率衰减到最终值 影响:决定训练后期的学习率大小 调整建议:0.01 表示最终学习率为初始值的 1% |
momentum | float | 0.937 | SGD 动量参数 | 作用:加速收敛并减少震荡 影响:过大可能导致过冲,过小收敛慢 调整建议:0.9-0.95 之间,通常保持默认值 |
weight_decay | float | 0.0005 | 权重衰减系数 | 作用:L2 正则化,防止过拟合 影响:过大导致欠拟合,过小可能过拟合 调整建议:小数据集增加,大数据集减少 |
warmup_epochs | float | 3.0 | 预热训练轮数 | 作用:逐渐增加学习率,稳定训练初期 影响:过短可能不稳定,过长浪费训练时间 调整建议:通常 2-5 轮,大数据集可减少 |
warmup_momentum | float | 0.8 | 预热阶段动量 | 作用:预热阶段的动量值 影响:影响预热阶段的收敛稳定性 调整建议:通常保持默认值,必要时微调 |
warmup_bias_lr | float | 0.1 | 预热阶段偏置学习率 | 作用:预热阶段偏置项的学习率 影响:影响模型偏置项的初始化 调整建议:通常保持默认值 |
学习率调优策略:
# 学习率调优函数
def optimize_learning_rate(dataset_size, model_complexity):
"""根据数据集大小和模型复杂度优化学习率"""
# 基础学习率
if dataset_size < 1000:
lr0 = 0.01
elif dataset_size < 10000:
lr0 = 0.01
else:
lr0 = 0.005
# 根据模型复杂度调整
if model_complexity == 'nano':
lr0 *= 1.2
elif model_complexity == 'small':
lr0 *= 1.0
elif model_complexity == 'medium':
lr0 *= 0.8
elif model_complexity == 'large':
lr0 *= 0.6
else: # xlarge
lr0 *= 0.4
return lr0
# 学习率调度器选择
def get_scheduler_config(optimizer_type, dataset_size):
"""选择合适的学习率调度器"""
if optimizer_type == 'SGD':
return {
'scheduler': 'cosine',
'cos_lr': True,
'lrf': 0.01
}
elif optimizer_type == 'Adam':
return {
'scheduler': 'linear',
'cos_lr': False,
'lrf': 0.1
}
else:
return {
'scheduler': 'auto',
'cos_lr': False,
'lrf': 0.01
}
3.2 学习率调度器参数
| 参数 | 类型 | 默认值 | 说明 | 作用与影响 |
|---|---|---|---|---|
cos_lr | bool | False | 是否使用余弦学习率调度 | 作用:控制学习率衰减曲线形状 影响:True 使用余弦衰减,False 使用线性衰减 调整建议:通常保持 False,需要平滑衰减时可开启 |
scheduler | str | 'auto' | 学习率调度器类型 | 作用:选择学习率调度策略 影响:影响学习率变化曲线和收敛效果 调整建议:'auto'自动选择,'cosine'余弦衰减,'linear'线性衰减 |
学习率调度器对比:
4. 数据增强参数详解
4.1 基础数据增强
| 参数 | 类型 | 默认值 | 说明 | 作用与影响 |
|---|---|---|---|---|
hsv_h | float | 0.015 | HSV 色调增强范围 | 作用:调整图像色调,模拟不同光照条件 影响:增强模型对光照变化的鲁棒性 调整建议:0.01-0.03,过大可能改变目标特征 |
hsv_s | float | 0.7 | HSV 饱和度增强范围 | 作用:调整图像饱和度,模拟不同色彩环境 影响:增强模型对色彩变化的适应性 调整建议:0.5-0.9,过大可能丢失重要色彩信息 |
hsv_v | float | 0.4 | HSV 亮度增强范围 | 作用:调整图像亮度,模拟不同光照强度 影响:增强模型对明暗变化的鲁棒性 调整建议:0.3-0.6,过大可能影响目标检测 |
degrees | float | 0.0 | 旋转角度范围 | 作用:随机旋转图像,增强旋转不变性 影响:提高模型对目标角度的适应性 调整建议:0-30 度,过大可能影响检测精度 |
translate | float | 0.1 | 平移范围 | 作用:随机平移图像,增强位置不变性 影响:提高模型对目标位置的适应性 调整建议:0.05-0.2,过大可能裁剪目标 |
scale | float | 0.5 | 缩放范围 | 作用:随机缩放图像,增强尺度不变性 影响:提高模型对不同目标大小的适应性 调整建议:0.3-0.7,过大可能影响小目标检测 |
shear | float | 0.0 | 剪切范围 | 作用:随机剪切图像,模拟视角变化 影响:增强模型对视角变化的鲁棒性 调整建议:0-15 度,过大可能扭曲目标形状 |
perspective | float | 0.0 | 透视变换范围 | 作用:随机透视变换,模拟 3D 视角变化 影响:增强模型对 3D 视角的适应性 调整建议:0-0.001,过大可能严重变形 |
flipud | float | 0.0 | 上下翻转概率 | 作用:随机上下翻转图像 影响:增强模型对上下翻转的鲁棒性 调整建议:0-0.5,注意目标是否有方向性 |
fliplr | float | 0.5 | 左右翻转概率 | 作用:随机左右翻转图像 影响:增强模型对左右翻转的鲁棒性 调整建议:0.3-0.7,注意目标是否有方向性 |
mosaic | float | 1.0 | Mosaic 增强概率 | 作用:将 4 张图像拼接,增加小目标样本 影响:显著提高小目标检测性能 调整建议:0.8-1.0,对小目标检测很重要 |
mixup | float | 0.0 | Mixup 增强概率 | 作用:混合两张图像和标签 影响:提高模型泛化能力,减少过拟合 调整建议:0.1-0.3,过大可能影响检测精度 |
copy_paste | float | 0.0 | 复制粘贴增强概率 | 作用:复制目标到其他图像 影响:增加目标样本数量,提高检测性能 调整建议:0.1-0.4,注意避免遮挡问题 |
数据增强配置示例:
# 基础数据增强配置
basic_augment = {
'hsv_h': 0.015, # 色调变化
'hsv_s': 0.7, # 饱和度变化
'hsv_v': 0.4, # 亮度变化
'degrees': 0.0, # 旋转角度
'translate': 0.1, # 平移范围
'scale': 0.5, # 缩放范围
'shear': 0.0, # 剪切变换
'perspective': 0.0, # 透视变换
'flipud': 0.0, # 上下翻转
'fliplr': 0.5, # 左右翻转
'mosaic': 1.0, # 马赛克增强
'mixup': 0.0, # 混合增强
'copy_paste': 0.0, # 复制粘贴
}
# 高级数据增强配置
advanced_augment = {
'erasing': 0.0, # 随机擦除
'auto_augment': None, # 自动增强
'grid_mask': 0.0, # 网格掩码
}
# 根据任务类型调整增强策略
def get_augment_config(task_type):
"""根据任务类型获取数据增强配置"""
if task_type == 'detect':
return {
'mosaic': 1.0,
'mixup': 0.0,
'copy_paste': 0.0,
'degrees': 0.0,
'translate': 0.1,
'scale': 0.5,
}
elif task_type == 'segment':
return {
'mosaic': 0.8,
'mixup': 0.1,
'copy_paste': 0.2,
'degrees': 10.0,
'translate': 0.1,
'scale': 0.5,
}
elif task_type == 'pose':
return {
'mosaic': 0.5,
'mixup': 0.0,
'copy_paste': 0.0,
'degrees': 5.0,
'translate': 0.05,
'scale': 0.3,
}
else:
return basic_augment
4.2 高级数据增强
| 参数 | 类型 | 默认值 | 说明 | 作用与影响 |
|---|---|---|---|---|
erasing | float | 0.0 | 随机擦除增强概率 | 作用:随机擦除图像区域,模拟遮挡情况 影响:提高模型对部分遮挡目标的鲁棒性 调整建议:0.1-0.3,过大可能影响检测精度 |
auto_augment | str | None | 自动数据增强策略 | 作用:自动选择最优的数据增强组合 影响:提高训练效率,但可能增加计算开销 调整建议:'randaugment'或'augmix',根据需求选择 |
grid_mask | float | 0.0 | 网格掩码增强概率 | 作用:应用网格状掩码,增强模型鲁棒性 影响:提高模型对遮挡和噪声的适应性 调整建议:0.1-0.2,过大可能影响目标完整性 |
高级增强策略:
# 自动增强配置
auto_augment_configs = {
'randaugment': {
'auto_augment': 'randaugment',
'magnitude': 9,
'num_layers': 2,
},
'augmix': {
'auto_augment': 'augmix',
'mixture_width': 3,
'mixture_depth': -1,
'aug_severity': 3,
},
'trivialaugment': {
'auto_augment': 'trivialaugment',
'num_magnitude_bins': 31,
}
}
# 根据数据集特点选择增强策略
def select_augment_strategy(dataset_characteristics):
"""根据数据集特点选择增强策略"""
if dataset_characteristics['small_objects']:
return {
'mosaic': 1.0,
'copy_paste': 0.3,
'mixup': 0.1,
}
elif dataset_characteristics['occlusion']:
return {
'erasing': 0.2,
'grid_mask': 0.1,
'mixup': 0.2,
}
elif dataset_characteristics['lighting_variation']:
return {
'hsv_h': 0.03,
'hsv_s': 0.8,
'hsv_v': 0.5,
}
else:
return basic_augment
高级训练参数
优化器参数
| 参数 | 类型 | 默认值 | 说明 | 作用与影响 |
|---|---|---|---|---|
lr0 | float | 0.01 | 初始学习率 | 作用:控制模型参数更新的步长大小 影响:过大导致训练不稳定,过小导致收敛缓慢 调整建议:小数据集用 0.01,大数据集用 0.005 |
lrf | float | 0.01 | 最终学习率因子(lr0 * lrf) | 作用:控制学习率衰减到最终值 影响:决定训练后期的学习率大小 调整建议:0.01 表示最终学习率为初始值的 1% |
momentum | float | 0.937 | SGD 动量参数 | 作用:加速收敛并减少震荡 影响:过大可能导致过冲,过小收敛慢 调整建议:0.9-0.95 之间,通常保持默认值 |
weight_decay | float | 0.0005 | 权重衰减系数 | 作用:L2 正则化,防止过拟合 影响:过大导致欠拟合,过小可能过拟合 调整建议:小数据集增加,大数据集减少 |
warmup_epochs | float | 3.0 | 预热训练轮数 | 作用:逐渐增加学习率,稳定训练初期 影响:过短可能不稳定,过长浪费训练时间 调整建议:通常 2-5 轮,大数据集可减少 |
warmup_momentum | float | 0.8 | 预热阶段动量 | 作用:预热阶段的动量值 影响:影响预热阶段的收敛稳定性 调整建议:通常保持默认值,必要时微调 |
warmup_bias_lr | float | 0.1 | 预热阶段偏置学习率 | 作用:预热阶段偏置项的学习率 影响:影响模型偏置项的初始化 调整建议:通常保持默认值 |
学习率调度器参数
| 参数 | 类型 | 默认值 | 说明 | 作用与影响 |
|---|---|---|---|---|
cos_lr | bool | False | 是否使用余弦学习率调度 | 作用:控制学习率衰减曲线形状 影响:True 使用余弦衰减,False 使用线性衰减 调整建议:通常保持 False,需要平滑衰减时可开启 |
scheduler | str | 'auto' | 学习率调度器类型 | 作用:选择学习率调度策略 影响:影响学习率变化曲线和收敛效果 调整建议:'auto'自动选择,'cosine'余弦衰减,'linear'线性衰减 |
数据增强参数
| 参数 | 类型 | 默认值 | 说明 | 作用与影响 |
|---|---|---|---|---|
hsv_h | float | 0.015 | HSV 色调增强范围 | 作用:调整图像色调,模拟不同光照条件 影响:增强模型对光照变化的鲁棒性 调整建议:0.01-0.03,过大可能改变目标特征 |
hsv_s | float | 0.7 | HSV 饱和度增强范围 | 作用:调整图像饱和度,模拟不同色彩环境 影响:增强模型对色彩变化的适应性 调整建议:0.5-0.9,过大可能丢失重要色彩信息 |
hsv_v | float | 0.4 | HSV 亮度增强范围 | 作用:调整图像亮度,模拟不同光照强度 影响:增强模型对明暗变化的鲁棒性 调整建议:0.3-0.6,过大可能影响目标检测 |
degrees | float | 0.0 | 旋转角度范围 | 作用:随机旋转图像,增强旋转不变性 影响:提高模型对目标角度的适应性 调整建议:0-30 度,过大可能影响检测精度 |
translate | float | 0.1 | 平移范围 | 作用:随机平移图像,增强位置不变性 影响:提高模型对目标位置的适应性 调整建议:0.05-0.2,过大可能裁剪目标 |
scale | float | 0.5 | 缩放范围 | 作用:随机缩放图像,增强尺度不变性 影响:提高模型对不同目标大小的适应性 调整建议:0.3-0.7,过大可能影响小目标检测 |
shear | float | 0.0 | 剪切范围 | 作用:随机剪切图像,模拟视角变化 影响:增强模型对视角变化的鲁棒性 调整建议:0-15 度,过大可能扭曲目标形状 |
perspective | float | 0.0 | 透视变换范围 | 作用:随机透视变换,模拟 3D 视角变化 影响:增强模型对 3D 视角的适应性 调整建议:0-0.001,过大可能严重变形 |
flipud | float | 0.0 | 上下翻转概率 | 作用:随机上下翻转图像 影响:增强模型对上下翻转的鲁棒性 调整建议:0-0.5,注意目标是否有方向性 |
fliplr | float | 0.5 | 左右翻转概率 | 作用:随机左右翻转图像 影响:增强模型对左右翻转的鲁棒性 调整建议:0.3-0.7,注意目标是否有方向性 |
mosaic | float | 1.0 | Mosaic 增强概率 | 作用:将 4 张图像拼接,增加小目标样本 影响:显著提高小目标检测性能 调整建议:0.8-1.0,对小目标检测很重要 |
mixup | float | 0.0 | Mixup 增强概率 | 作用:混合两张图像和标签 影响:提高模型泛化能力,减少过拟合 调整建议:0.1-0.3,过大可能影响检测精度 |
copy_paste | float | 0.0 | 复制粘贴增强概率 | 作用:复制目标到其他图像 影响:增加目标样本数量,提高检测性能 调整建议:0.1-0.4,注意避免遮挡问题 |
高级数据增强参数
| 参数 | 类型 | 默认值 | 说明 | 作用与影响 |
|---|---|---|---|---|
erasing | float | 0.0 | 随机擦除增强概率 | 作用:随机擦除图像区域,模拟遮挡情况 影响:提高模型对部分遮挡目标的鲁棒性 调整建议:0.1-0.3,过大可能影响检测精度 |
auto_augment | str | None | 自动数据增强策略 | 作用:自动选择最优的数据增强组合 影响:提高训练效率,但可能增加计算开销 调整建议:'randaugment'或'augmix',根据需求选择 |
grid_mask | float | 0.0 | 网格掩码增强概率 | 作用:应用网格状掩码,增强模型鲁棒性 影响:提高模型对遮挡和噪声的适应性 调整建议:0.1-0.2,过大可能影响目标完整性 |
损失函数参数
| 参数 | 类型 | 默认值 | 说明 | 作用与影响 |
|---|---|---|---|---|
box | float | 7.5 | 边界框损失权重 | 作用:控制边界框回归损失的重要性 影响:过大导致边界框精度过高但分类差,过小导致定位不准 调整建议:通常保持默认值,定位要求高时可增加 |
cls | float | 0.5 | 分类损失权重 | 作用:控制分类损失的重要性 影响:过大导致分类精度高但定位差,过小导致分类错误 调整建议:通常保持默认值,分类要求高时可增加 |
dfl | float | 1.5 | 分布焦点损失权重 | 作用:控制分布焦点损失的重要性 影响:过大可能影响其他损失,过小可能降低检测精度 调整建议:通常保持默认值,必要时微调 |
pose | float | 12.0 | 姿态估计损失权重 | 作用:控制姿态估计损失的重要性 影响:过大导致姿态精度高但检测差,过小导致姿态不准 调整建议:仅姿态估计任务使用,检测任务设为 0 |
kobj | float | 2.0 | 关键点目标损失权重 | 作用:控制关键点检测损失的重要性 影响:过大导致关键点精度高但检测差,过小导致关键点不准 调整建议:仅关键点检测任务使用,检测任务设为 0 |
label_smoothing | float | 0.0 | 标签平滑系数 | 作用:标签平滑,减少过拟合 影响:过大导致训练不稳定,过小效果不明显 调整建议:0.0-0.1,小数据集可适当增加 |
模型架构参数
| 参数 | 类型 | 默认值 | 说明 | 作用与影响 |
|---|---|---|---|---|
anchors | int | 9 | 每层的锚框数量 | 作用:控制每层特征图的锚框数量 影响:影响检测精度和计算复杂度 调整建议:通常保持默认值,小目标检测可适当增加 |
overlap_mask | bool | True | 是否处理掩码重叠 | 作用:控制分割任务中掩码重叠的处理方式 影响:影响分割精度和计算效率 调整建议:分割任务保持 True,检测任务可设为 False |
mask_ratio | int | 4 | 掩码下采样比例 | 作用:控制分割掩码的下采样比例 影响:影响分割精度和内存占用 调整建议:通常保持默认值,精度要求高时可减小到 2 |
验证和评估参数
| 参数 | 类型 | 默认值 | 说明 | 作用与影响 |
|---|---|---|---|---|
val | bool | True | 是否在训练过程中进行验证 | 作用:控制是否在训练过程中进行验证 影响:开启可监控训练进度,关闭可加快训练速度 调整建议:通常保持开启,大数据集训练时可关闭 |
plots | bool | True | 是否生成训练图表 | 作用:控制是否生成训练过程图表 影响:开启可分析训练趋势,关闭可节省存储空间 调整建议:调试时开启,生产环境可关闭 |
save_json | bool | False | 是否保存 COCO 格式的 JSON 结果 | 作用:控制是否保存 COCO 格式的检测结果 影响:开启可用于 COCO 评估,关闭节省存储空间 调整建议:需要 COCO 评估时开启,否则关闭 |
save_hybrid | bool | False | 是否保存混合标签结果 | 作用:控制是否保存混合标签的检测结果 影响:开启可用于混合标签评估,关闭节省存储空间 调整建议:需要混合标签评估时开启,否则关闭 |
conf | float | 0.001 | 验证时置信度阈值 | 作用:控制验证时的置信度过滤阈值 影响:过低可能包含噪声,过高可能漏检 调整建议:0.001-0.01,根据应用场景调整 |
iou | float | 0.6 | 验证时 NMS IoU 阈值 | 作用:控制验证时的 NMS IoU 阈值 影响:过低可能重复检测,过高可能漏检 调整建议:0.5-0.7,密集目标检测时可降低 |
max_det | int | 300 | 每张图像最大检测数量 | 作用:控制每张图像的最大检测数量 影响:过低可能漏检,过高可能包含噪声 调整建议:100-500,根据图像复杂度和应用需求调整 |
训练策略参数
| 参数 | 类型 | 默认值 | 说明 | 作用与影响 |
|---|---|---|---|---|
close_mosaic | int | 10 | 关闭马赛克增强的轮数 | 作用:训练后期关闭马赛克增强 影响:提高训练稳定性,减少过拟合 调整建议:通常保持默认值,过拟合时可提前关闭 |
rect | bool | False | 是否使用矩形训练 | 作用:保持图像原始宽高比进行训练 影响:减少图像变形,提高检测精度 调整建议:目标形状重要时开启,否则保持 False |
multi_scale | bool | False | 是否使用多尺度训练 | 作用:训练时随机改变图像尺寸 影响:提高模型对不同尺寸目标的适应性 调整建议:小目标检测任务建议开启,提高泛化能力 |
参数调整指南
核心参数详解
1. 学习率相关参数
lr0 (初始学习率)
- 作用原理:控制模型参数更新的步长大小,是训练过程中最重要的超参数
- 调整策略:
- 小数据集(<1000 张):使用 0.01,因为数据少需要较大步长快速收敛
- 中等数据集(1000-10000 张):使用 0.01,标准配置
- 大数据集(>10000 张):使用 0.005,数据充足可用较小步长精细调优
- 调整效果:
- 过大(>0.02):训练不稳定,损失震荡,可能无法收敛
- 过小(<0.001):收敛缓慢,训练时间长,可能陷入局部最优
lrf (最终学习率因子)
- 作用原理:控制学习率从初始值衰减到最终值的比例
- 调整策略:通常保持 0.01,表示最终学习率为初始值的 1%
- 调整效果:
- 过大(>0.1):学习率衰减过快,后期训练效果差
- 过小(<0.001):学习率衰减过慢,可能过拟合
2. 正则化参数
weight_decay (权重衰减)
- 作用原理:L2 正则化,通过惩罚大权重值防止过拟合
- 调整策略:
- 小数据集:增加到 0.001,防止过拟合
- 大数据集:减少到 0.0001,数据充足时不需要强正则化
- 调整效果:
- 过大:模型欠拟合,训练和验证损失都高
- 过小:可能过拟合,验证损失高但训练损失低
label_smoothing (标签平滑)
- 作用原理:将硬标签转换为软标签,减少模型对标签的过度自信
- 调整策略:0.0-0.1,小数据集可适当增加
- 调整效果:
- 过大:训练不稳定,收敛困难
- 过小:效果不明显
3. 数据增强参数
mosaic (Mosaic 增强)
- 作用原理:将 4 张图像拼接成一张,增加小目标样本数量
- 调整策略:0.8-1.0,对小目标检测至关重要
- 调整效果:
- 开启:显著提高小目标检测性能,但可能影响大目标
- 关闭:小目标检测性能下降
mixup (Mixup 增强)
- 作用原理:混合两张图像和标签,提高模型泛化能力
- 调整策略:0.1-0.3,过大可能影响检测精度
- 调整效果:
- 适当使用:减少过拟合,提高泛化能力
- 过度使用:检测精度下降
4. 损失函数权重
box (边界框损失权重)
- 作用原理:控制边界框回归损失在总损失中的重要性
- 调整策略:通常保持 7.5,定位要求高时可增加到 10
- 调整效果:
- 过大:边界框精度高但分类性能差
- 过小:定位不准,检测框偏移
cls (分类损失权重)
- 作用原理:控制分类损失在总损失中的重要性
- 调整策略:通常保持 0.5,分类要求高时可增加到 1.0
- 调整效果:
- 过大:分类精度高但定位性能差
- 过小:分类错误,目标类别识别错误
5. 学习率调度器参数
cos_lr (余弦学习率调度)
- 作用原理:控制学习率衰减曲线形状,True 使用余弦衰减,False 使用线性衰减
- 调整策略:通常保持 False,需要平滑衰减时可开启
- 调整效果:
- 开启:学习率衰减更平滑,后期训练更稳定
- 关闭:学习率线性衰减,收敛更快但可能不够平滑
scheduler (学习率调度器类型)
- 作用原理:选择学习率调度策略,影响学习率变化曲线
- 调整策略:'auto' 自动选择,'cosine' 余弦衰减,'linear' 线性衰减
- 调整效果:
- 'auto':自动选择最适合的调度策略
- 'cosine':余弦衰减,适合长期训练
- 'linear':线性衰减,适合快速收敛
6. 高级数据增强参数
erasing (随机擦除增强)
- 作用原理:随机擦除图像区域,模拟遮挡情况
- 调整策略:0.1-0.3,过大可能影响检测精度
- 调整效果:
- 适当使用:提高模型对部分遮挡目标的鲁棒性
- 过度使用:可能擦除重要目标信息
auto_augment (自动数据增强策略)
- 作用原理:自动选择最优的数据增强组合
- 调整策略:'randaugment' 或 'augmix',根据需求选择
- 调整效果:
- 开启:提高训练效率,自动优化增强策略
- 关闭:手动控制增强参数,更灵活但需要经验
grid_mask (网格掩码增强)
- 作用原理:应用网格状掩码,增强模型鲁棒性
- 调整策略:0.1-0.2,过大可能影响目标完整性
- 调整效果:
- 适当使用:提高模型对遮挡和噪声的适应性
- 过度使用:可能过度遮挡目标
7. 模型架构参数
anchors (锚框数量)
- 作用原理:控制每层特征图的锚框数量
- 调整策略:通常保持默认值 9,小目标检测可适当增加
- 调整效果:
- 增加:提高检测精度但增加计算复杂度
- 减少:降低计算复杂度但可能影响检测精度
overlap_mask (掩码重叠处理)
- 作用原理:控制分割任务中掩码重叠的处理方式
- 调整策略:分割任务保持 True,检测任务可设为 False
- 调整效果:
- 开启:提高分割精度但增加计算开销
- 关闭:减少计算开销但可能影响分割质量
mask_ratio (掩码下采样比例)
- 作用原理:控制分割掩码的下采样比例
- 调整策略:通常保持默认值 4,精度要求高时可减小到 2
- 调整效果:
- 减小:提高分割精度但增加内存占用
- 增大:减少内存占用但可能降低分割精度
8. 训练策略参数
close_mosaic (关闭马赛克增强的轮数)
- 作用原理:训练后期关闭马赛克增强,提高训练稳定性
- 调整策略:通常保持默认值 10,过拟合时可提前关闭
- 调整效果:
- 过早关闭:可能影响小目标检测性能
- 过晚关闭:可能增加过拟合风险
rect (矩形训练)
- 作用原理:保持图像原始宽高比进行训练,减少图像变形
- 调整策略:目标形状重要时开启,否则保持 False
- 调整效果:
- 开启:减少图像变形,提高检测精度
- 关闭:可能增加图像变形,但训练更灵活
multi_scale (多尺度训练)
- 作用原理:训练时随机改变图像尺寸,提高模型适应性
- 调整策略:小目标检测任务建议开启,提高泛化能力
- 调整效果:
- 开启:提高模型对不同尺寸目标的适应性
- 关闭:训练更稳定,但泛化能力可能降低
根据数据集大小调整
# 小数据集(<1000张图像)
results = model.train(
data='data.yaml',
epochs=300, # 增加训练轮数
imgsz=640,
batch=8, # 减小批次大小
lr0=0.01, # 标准学习率
weight_decay=0.001, # 增加正则化
patience=100, # 增加早停耐心值
cache=True, # 开启缓存
)
# 中等数据集(1000-10000张图像)
results = model.train(
data='data.yaml',
epochs=200, # 标准训练轮数
imgsz=640,
batch=16, # 标准批次大小
lr0=0.01, # 标准学习率
weight_decay=0.0005, # 标准正则化
patience=50, # 标准早停耐心值
)
# 大数据集(>10000张图像)
results = model.train(
data='data.yaml',
epochs=100, # 减少训练轮数
imgsz=640,
batch=32, # 增加批次大小
lr0=0.005, # 降低学习率
weight_decay=0.0001, # 减少正则化
patience=30, # 减少早停耐心值
)
根据硬件配置调整
# 高显存GPU(>16GB)
results = model.train(
data='data.yaml',
epochs=100,
imgsz=640,
batch=32, # 大批次
workers=16, # 多线程
amp=True, # 混合精度
cache=True, # 开启缓存
)
# 中等显存GPU(8-16GB)
results = model.train(
data='data.yaml',
epochs=100,
imgsz=640,
batch=16, # 中等批次
workers=8, # 中等线程
amp=True, # 混合精度
cache=False, # 关闭缓存
)
# 低显存GPU(<8GB)
results = model.train(
data='data.yaml',
epochs=100,
imgsz=512, # 减小图像尺寸
batch=8, # 小批次
workers=4, # 少线程
amp=True, # 混合精度
cache=False, # 关闭缓存
)
根据任务类型调整
# 目标检测任务
results = model.train(
data='data.yaml',
epochs=100,
imgsz=640,
batch=16,
box=7.5, # 边界框损失权重
cls=0.5, # 分类损失权重
dfl=1.5, # 分布焦点损失权重
)
# 实例分割任务
results = model.train(
data='data.yaml',
epochs=150, # 增加训练轮数
imgsz=640,
batch=16,
box=7.5, # 边界框损失权重
cls=0.5, # 分类损失权重
dfl=1.5, # 分布焦点损失权重
# 分割任务可能需要更多训练
)
# 姿态估计任务
results = model.train(
data='data.yaml',
epochs=200, # 增加训练轮数
imgsz=640,
batch=16,
box=7.5, # 边界框损失权重
cls=0.5, # 分类损失权重
pose=12.0, # 姿态损失权重
kobj=2.0, # 关键点目标损失权重
)
训练监控和调试
实时监控训练状态
# 开启详细输出和实时监控
results = model.train(
data='data.yaml',
epochs=100,
verbose=True, # 详细输出
plots=True, # 生成图表
save_period=10, # 定期保存
val=True, # 定期验证
)
训练中断和恢复
# 从断点恢复训练
results = model.train(
data='data.yaml',
epochs=100,
resume=True, # 恢复训练
# 其他参数会自动从上次训练中读取
)
多 GPU 训练
# 使用多个GPU进行分布式训练
results = model.train(
data='data.yaml',
epochs=100,
device='0,1,2,3', # 使用4个GPU
batch=64, # 总批次大小(每个GPU 16)
workers=32, # 总线程数
)
常见问题解决
显存不足
# 减少显存占用
results = model.train(
data='data.yaml',
epochs=100,
imgsz=512, # 减小图像尺寸
batch=8, # 减小批次大小
workers=4, # 减少线程数
cache=False, # 关闭缓存
amp=True, # 开启混合精度
)
训练不收敛
# 调整学习率和正则化
results = model.train(
data='data.yaml',
epochs=100,
lr0=0.001, # 降低学习率
weight_decay=0.001, # 增加正则化
patience=100, # 增加早停耐心值
warmup_epochs=5, # 增加预热轮数
)
过拟合问题
# 防止过拟合
results = model.train(
data='data.yaml',
epochs=100,
weight_decay=0.001, # 增加正则化
label_smoothing=0.1, # 标签平滑
hsv_h=0.015, # 增加数据增强
hsv_s=0.7,
hsv_v=0.4,
degrees=10.0, # 增加旋转
translate=0.2, # 增加平移
scale=0.9, # 增加缩放
)
问题 4:检测框定位不准
- 可能原因:
box损失权重过低、数据增强过强 - 解决方案:增加
box权重、减少几何变换增强
问题 5:学习率衰减过快或过慢
- 可能原因:
cos_lr设置不当、scheduler选择不合适 - 解决方案:调整
cos_lr设置、选择合适的scheduler策略
问题 6:高级数据增强效果不佳
- 可能原因:
erasing、grid_mask等参数设置不当 - 解决方案:调整增强概率、根据任务特点选择合适的增强策略
问题 7:分割任务性能差
- 可能原因:
overlap_mask、mask_ratio设置不当 - 解决方案:调整掩码处理参数、优化下采样比例
模型使用
基础推理
使用训练好的模型进行目标检测:
from ultralytics import YOLO
# 加载训练好的模型
model = YOLO('runs/train/exp/weights/best.pt') # 加载最佳权重
# model = YOLO('runs/train/exp/weights/last.pt') # 加载最后权重
# 对单张图片进行推理
results = model('path/to/image.jpg')
# 对多张图片进行推理
results = model(['image1.jpg', 'image2.jpg', 'image3.jpg'])
# 对视频进行推理
results = model('video.mp4')
# 对摄像头进行实时推理
results = model(source=0, show=True) # 0表示默认摄像头
预测参数配置
# 自定义预测参数
results = model.predict(
source='path/to/images', # 图片路径
conf=0.5, # 置信度阈值
iou=0.45, # NMS IoU阈值
imgsz=640, # 输入图像尺寸
save=True, # 保存结果
save_txt=True, # 保存标签文件
save_conf=True, # 保存置信度
save_crop=True, # 保存裁剪的目标
project='runs/detect', # 项目目录
name='exp', # 实验名称
exist_ok=True, # 覆盖现有目录
line_thickness=3, # 边界框线条粗细
hide_labels=False, # 隐藏标签
hide_conf=False, # 隐藏置信度
half=False, # 使用FP16推理
dnn=False, # 使用OpenCV DNN
vid_stride=1, # 视频帧间隔
stream_buffer=False, # 流缓冲区
visualize=False, # 可视化特征
augment=False, # 测试时增强
agnostic_nms=False, # 类别无关NMS
retina_masks=False, # 高分辨率掩码
classes=None, # 过滤类别
max_det=300, # 最大检测数量
verbose=True, # 详细输出
)
结果处理
# 处理推理结果
for result in results:
boxes = result.boxes # 边界框
masks = result.masks # 分割掩码
keypoints = result.keypoints # 关键点
probs = result.probs # 分类概率
# 获取边界框信息
if boxes is not None:
# 坐标信息
xyxy = boxes.xyxy # 左上右下坐标
xywh = boxes.xywh # 中心点宽高
xyxyn = boxes.xyxyn # 归一化坐标
xywhn = boxes.xywhn # 归一化中心点宽高
# 置信度和类别
conf = boxes.conf # 置信度
cls = boxes.cls # 类别ID
cls_names = boxes.cls_names # 类别名称
# 打印检测结果
for i in range(len(boxes)):
print(f"检测到 {cls_names[i]}: 置信度 {conf[i]:.2f}")
print(f"坐标: {xyxy[i]}")
模型验证
# 在验证集上评估模型性能
results = model.val(
data='data.yaml', # 数据集配置
split='val', # 验证集分割
imgsz=640, # 图像尺寸
batch=16, # 批次大小
device=0, # GPU设备
workers=8, # 数据加载线程
project='runs/val', # 项目目录
name='exp', # 实验名称
exist_ok=True, # 覆盖现有目录
half=True, # 使用FP16
dnn=False, # 使用OpenCV DNN
plots=True, # 生成评估图表
save=True, # 保存结果
save_json=False, # 保存JSON结果
save_hybrid=False, # 保存混合标签
conf=0.001, # 置信度阈值
iou=0.6, # NMS IoU阈值
max_det=300, # 最大检测数量
verbose=True, # 详细输出
)
模型信息
# 获取模型信息
model.info() # 显示模型详细信息
# 获取模型参数数量
total_params = sum(p.numel() for p in model.parameters())
print(f"模型总参数量: {total_params:,}")
# 获取模型结构
print(model.model) # 显示模型架构
# 获取模型配置
print(model.model.yaml) # 显示模型配置
模型转换
导出格式
YOLO11 支持多种导出格式,适用于不同的部署环境:
# 导出不同格式的模型
model = YOLO('runs/train/exp/weights/best.pt')
# 导出为 ONNX 格式(推荐用于跨平台部署)
model.export(format='onnx',
imgsz=640,
half=True,
simplify=True)
# 导出为 TensorRT 格式(NVIDIA GPU 加速)
model.export(format='engine',
imgsz=640,
half=True,
device=0)
# 导出为 OpenVINO 格式(Intel CPU/GPU 优化)
model.export(format='openvino',
imgsz=640,
half=True)
# 导出为 CoreML 格式(Apple 设备)
model.export(format='coreml',
imgsz=640,
half=True)
# 导出为 TensorFlow SavedModel 格式
model.export(format='saved_model',
imgsz=640,
half=True)
# 导出为 TensorFlow GraphDef 格式
model.export(format='pb',
imgsz=640,
half=True)
# 导出为 TFLite 格式(移动端部署)
model.export(format='tflite',
imgsz=640,
half=True,
int8=True) # 量化
# 导出为 PaddlePaddle 格式
model.export(format='paddle',
imgsz=640,
half=True)
# 导出为 TorchScript 格式
model.export(format='torchscript',
imgsz=640,
half=True)
导出参数详解
# 详细导出配置
model.export(
format='onnx', # 导出格式
imgsz=640, # 输入图像尺寸
batch=1, # 批次大小
device='cpu', # 设备类型
half=True, # 使用FP16
int8=False, # 使用INT8量化
simplify=True, # 简化模型
opset=11, # ONNX算子集版本
workspace=4, # TensorRT工作空间(GB)
nms=False, # 包含NMS
agnostic_nms=False, # 类别无关NMS
topk_all=100, # 所有类别的top-k
iou_thres=0.65, # IoU阈值
conf_thres=0.25, # 置信度阈值
include_nms=True, # 包含NMS层
keras=False, # 使用Keras格式
optimize=False, # 优化模型
int8_calib_dataset=None, # INT8校准数据集
int8_calib_algorithm='entropy', # 校准算法
data=None, # 数据集配置
verbose=True, # 详细输出
)
部署示例
ONNX 部署
import onnxruntime as ort
import numpy as np
import cv2
# 加载ONNX模型
session = ort.InferenceSession('best.onnx')
# 预处理图像
def preprocess_image(image_path, input_size=(640, 640)):
img = cv2.imread(image_path)
img = cv2.resize(img, input_size)
img = img.transpose(2, 0, 1) # HWC to CHW
img = np.expand_dims(img, axis=0)
img = img.astype(np.float32) / 255.0
return img
# 推理
image = preprocess_image('test.jpg')
outputs = session.run(None, {'images': image})
训练图详解
混淆矩阵图解释
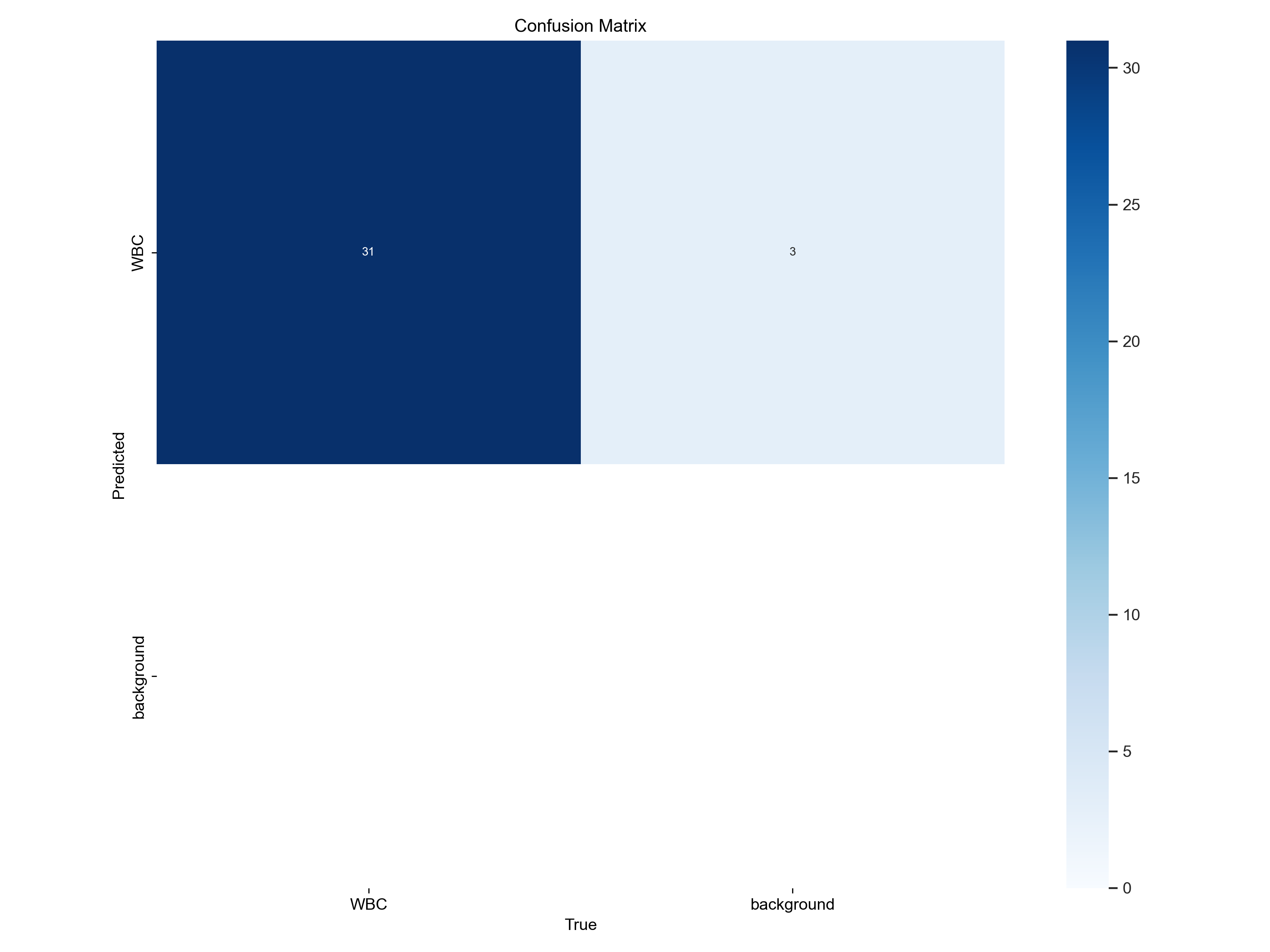
图表概述: 这是一个用于评估目标检测模型性能的混淆矩阵图,标题为"Confusion Matrix",展示了模型在"WBC"(白细胞)和"background"(背景)两个类别上的分类性能。
图表结构详解:
Y 轴(Predicted - 预测值): 表示模型对样本的预测类别
- WBC:白细胞
- background:背景
X 轴(True - 真实值): 表示样本的真实类别
- WBC:白细胞
- background:背景
矩阵单元格数值分析:
左上角 (True: WBC, Predicted: WBC) - 数值 31:
- 含义: 真阳性(True Positives)
- 解释: 模型正确地将 31 个白细胞样本识别为白细胞
- 性能: 这是模型的主要成功案例,表明模型在识别白细胞方面表现良好
- 颜色: 深蓝色,表示该单元格数值较高
右上角 (True: background, Predicted: WBC) - 数值 3:
- 含义: 假阳性(False Positives)
- 解释: 模型错误地将 3 个背景样本识别为白细胞
- 性能: 这是模型的误报情况,需要关注
- 颜色: 浅蓝色,表示该单元格数值较低
左下角 (True: WBC, Predicted: background) - 数值 0:
- 含义: 假阴性(False Negatives)
- 解释: 模型没有将任何白细胞样本错误地识别为背景
- 性能: 这是模型的良好表现,没有漏检白细胞
- 颜色: 白色,表示该单元格数值为零
右下角 (True: background, Predicted: background) - 数值 0:
- 含义: 真阴性(True Negatives)
- 解释: 模型没有正确识别任何背景样本
- 性能: 这可能表明数据集中背景样本数量较少
- 颜色: 白色,表示该单元格数值为零
颜色条说明: 右侧的颜色条显示了矩阵中数值对应的颜色深浅,从白色(0)到深蓝色(30+)渐变,数值越大颜色越深。
模型性能总结:
优点:
- 模型在识别白细胞方面表现良好,成功识别了 31 个白细胞
- 没有出现漏检白细胞的情况(假阴性为 0)
- 整体识别准确率较高
需要改进的地方:
- 存在 3 个误报情况,将背景识别为白细胞
- 模型在背景类别上的识别能力有待提升
- 可能需要增加背景样本的训练数据
建议:
- 增加背景样本的训练数据
- 调整模型的置信度阈值
- 优化数据增强策略
- 考虑使用类别平衡的损失函数
归一化混淆矩阵图解释
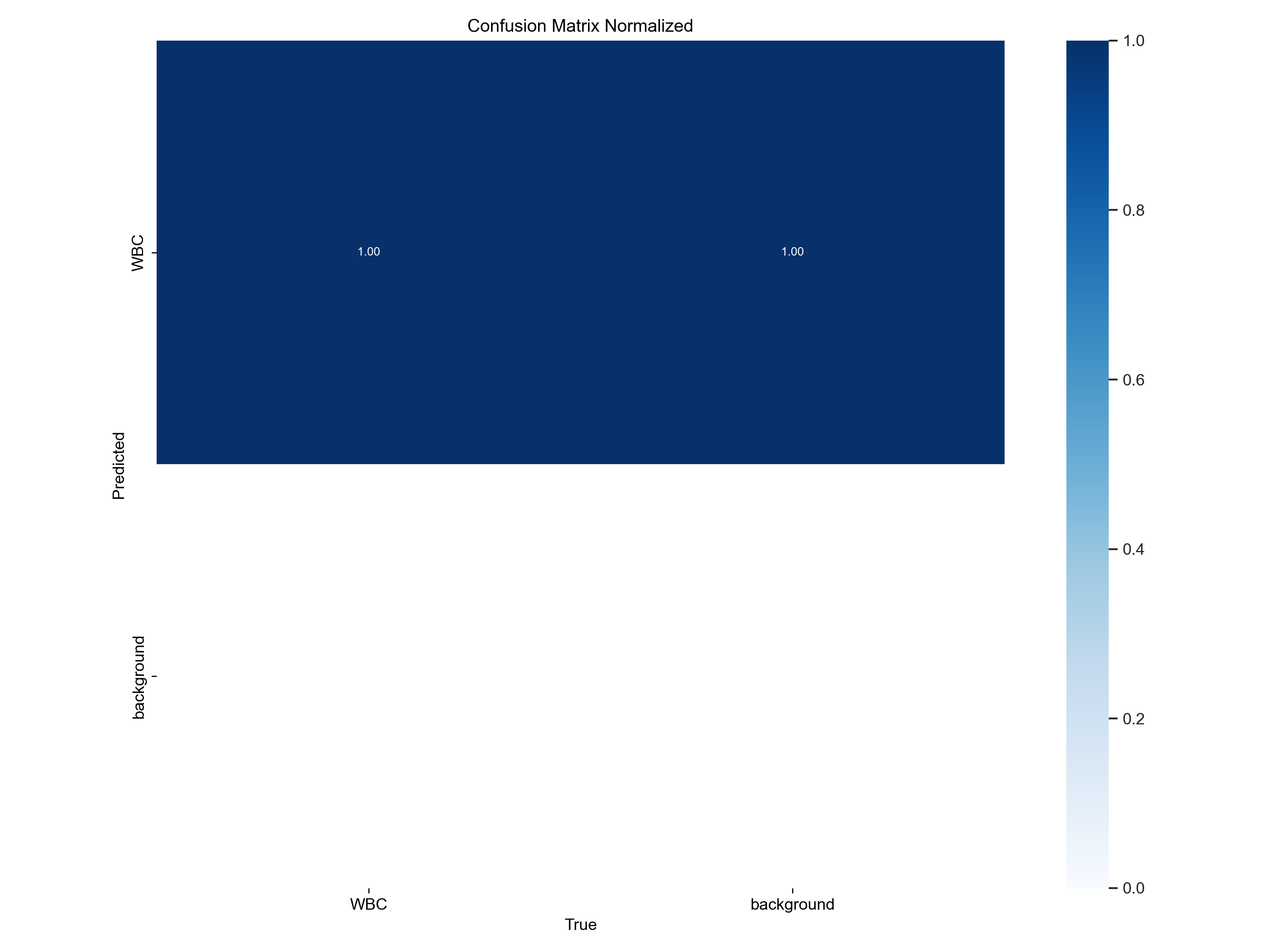
图表概述: 这是一个归一化的混淆矩阵图,标题为"Confusion Matrix Normalized",用于评估目标检测模型在"WBC"(白细胞)和"background"(背景)两个类别上的分类性能。图中的数值表示的是分类的比例或准确率,而非原始计数。
图表结构详解:
Y 轴(Predicted - 预测值): 表示模型对样本的预测类别
- WBC:白细胞
- background:背景
X 轴(True - 真实值): 表示样本的真实类别
- WBC:白细胞
- background:背景
矩阵单元格数值分析:
左上角 (True: WBC, Predicted: WBC) - 数值 1.00:
- 含义: 真阳性率(True Positive Rate / Recall for WBC)
- 解释: 模型正确地将所有(100%)真实的白细胞样本识别为白细胞
- 性能: 这是模型的完美表现,表明模型在识别白细胞方面没有漏报
- 颜色: 深蓝色,与颜色条的 1.0 值对应,表示该单元格数值最高
右上角 (True: background, Predicted: WBC) - 数值 0.00:
- 含义: 假阳性率(False Positive Rate for WBC)
- 解释: 模型没有将任何背景样本错误地识别为白细胞
- 性能: 这是模型的完美表现,表明模型没有误报背景为白细胞
- 颜色: 浅蓝色,与颜色条的 0.0 值对应
左下角 (True: WBC, Predicted: background) - 数值 0.00:
- 含义: 假阴性率(False Negative Rate for WBC)
- 解释: 模型没有将任何白细胞样本错误地识别为背景
- 性能: 这是模型的完美表现,表明模型没有漏检白细胞
- 颜色: 浅蓝色,与颜色条的 0.0 值对应
右下角 (True: background, Predicted: background) - 数值 1.00:
- 含义: 真阴性率(True Negative Rate / Recall for background)
- 解释: 模型正确地将所有(100%)真实的背景样本识别为背景
- 性能: 这是模型的完美表现,表明模型在识别背景方面没有漏报
- 颜色: 深蓝色,与颜色条的 1.0 值对应,表示该单元格数值最高
颜色条说明: 颜色条从浅蓝色(0.0)到深蓝色(1.0)表示单元格数值的大小。数值越大,颜色越深。
归一化与原始混淆矩阵的区别:
- 原始混淆矩阵: 显示的是绝对计数,如 31 个真阳性、3 个假阳性等
- 归一化混淆矩阵: 显示的是比例或准确率,如 1.00 表示 100%的准确率
- 归一化优势: 消除了样本数量不平衡的影响,更直观地反映模型的分类性能
模型性能总结:
根据这个归一化混淆矩阵,模型在白细胞(WBC)和背景(background)这两个类别上的分类性能达到了完美:
优点:
- 所有真实白细胞都被正确识别为白细胞(召回率 100%)
- 所有真实背景都被正确识别为背景(召回率 100%)
- 没有出现误报或漏报的情况
- 模型实现了 100%的准确率、精确率和召回率
性能指标:
- 准确率(Accuracy): 100%
- 精确率(Precision): 100%
- 召回率(Recall): 100%
- F1 分数: 100%
结论: 这个归一化混淆矩阵表明模型在当前测试数据集上表现完美,能够准确区分白细胞和背景。这种完美的性能可能表明:
- 测试数据集相对简单
- 模型已经过充分训练
- 数据集中的样本特征区分度很高
F1-置信度 曲线图解释
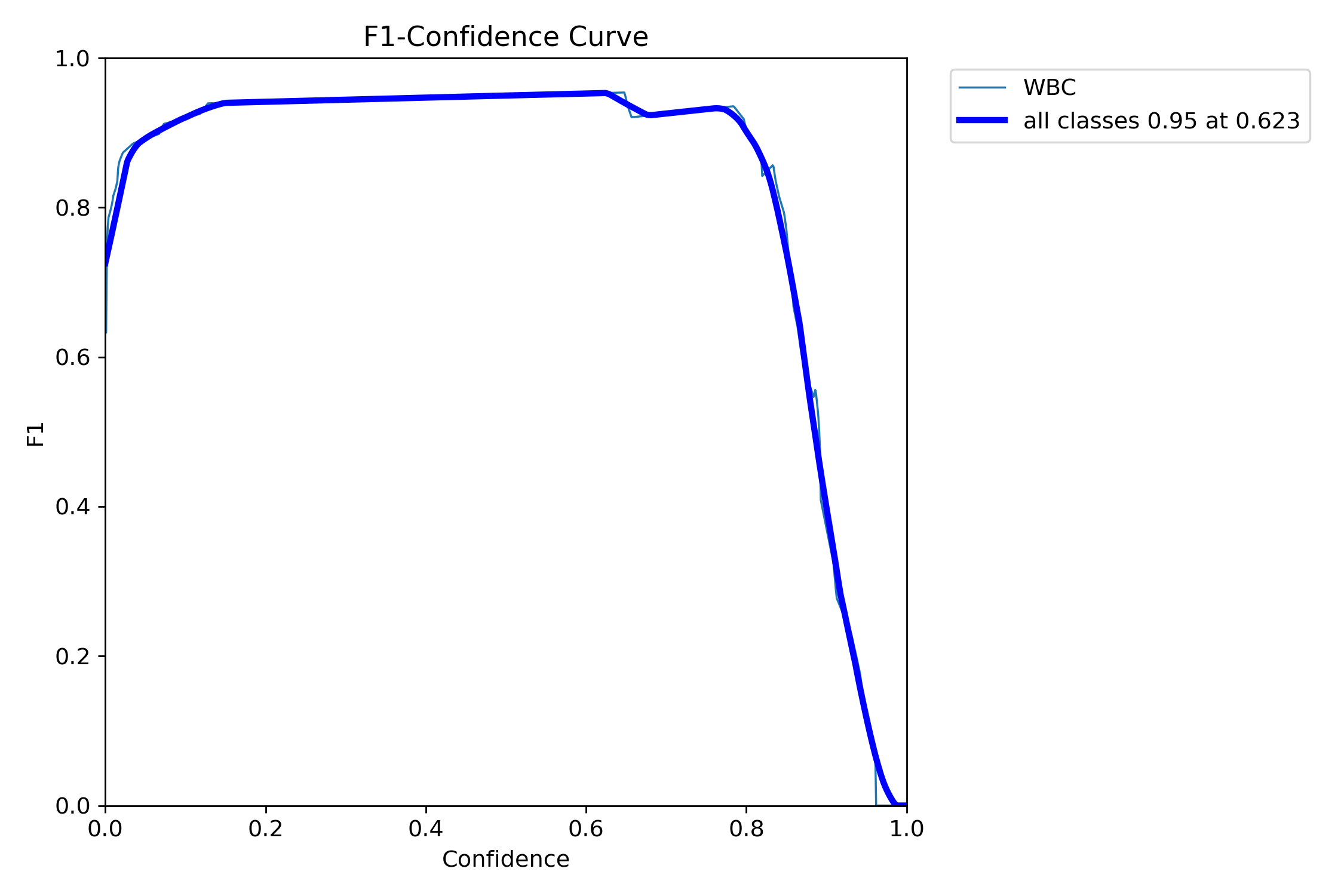
图表概述: 这是一个 F1-Confidence (F1-置信度) 曲线图,用于评估目标检测模型在不同置信度阈值下的性能。它展示了 F1 分数(F1-score)如何随预测置信度(Confidence)的变化而变化。F1 分数是精确率(Precision)和召回率(Recall)的调和平均值,是衡量模型综合性能的重要指标。
图表结构详解:
- X 轴(Confidence - 置信度): 表示模型输出的预测置信度阈值,范围从 0.0 到 1.0。当置信度阈值越高,模型只保留那些它"非常确定"的预测结果。
- Y 轴(F1 - F1 分数): 表示模型在对应置信度阈值下的 F1 分数,范围从 0.0 到 1.0。F1 分数越高,表示模型的精确率和召回率越平衡且越高。
曲线分析:
"WBC"曲线(细青色线):
- 代表模型在"WBC"(白细胞)单一类别上的 F1 分数表现。
- 曲线趋势与"all classes"曲线相似,表明该类别与整体性能趋势一致。
"all classes"曲线(粗蓝色线):
- 代表模型在所有类别上的平均 F1 分数表现。
- 初始阶段(Confidence 0.0 - 约 0.15): 曲线从 F1 分数约 0.75 迅速上升。这表明在非常低的置信度阈值下,模型会包含大量预测,其中可能包含较多假阳性,导致 F1 分数相对较低。随着置信度阈值的略微提高,模型开始过滤掉一些低质量的预测,F1 分数迅速提升。
- 平台期(Confidence 约 0.15 - 约 0.7): 曲线达到并保持在一个较高的 F1 分数平台,大约在 0.95-0.96 之间。这表示在这个置信度范围内,模型能够保持非常好的综合性能,精确率和召回率都处于高水平。
- 关键点: 粗蓝色线上标注了"all classes 0.95 at 0.623"。这表示当置信度阈值设置为 0.623 时,模型的平均 F1 分数达到了 0.95。这个点通常被认为是模型的最佳操作点,因为它在保持高 F1 分数的同时,选择了一个相对较高的置信度,有助于减少不确定性预测。
- 下降阶段(Confidence 约 0.7 - 1.0): 曲线开始急剧下降,最终接近 0。这表明当置信度阈值设置得过高时(例如 0.7 以上),模型会变得过于严格,只保留极少数它"非常确定"的预测。这会导致召回率大幅下降(因为很多真实目标可能因为置信度略低于阈值而被忽略),从而使 F1 分数迅速降低。
图表结论:
- 该模型在目标检测任务上表现出色,能够达到非常高的 F1 分数(接近 0.95)。
- 在置信度阈值 0.15 到 0.7 之间,模型性能稳定且优秀。
- 推荐的置信度阈值: 根据曲线,将置信度阈值设置为 0.623 是一个很好的选择,因为它在此处实现了 0.95 的 F1 分数,代表了精确率和召回率的良好平衡。
- 过高或过低的置信度阈值都会导致模型性能下降,尤其是在置信度阈值过高时,模型会变得过于保守,导致大量漏检。
实际应用建议:
- 生产环境设置: 建议将置信度阈值设置为 0.623,这是模型性能的最佳平衡点。
- 实时检测: 如果需要更快的推理速度,可以适当降低置信度阈值到 0.5 左右。
- 高精度要求: 如果对精度要求极高,可以将置信度阈值提高到 0.7,但要注意这会导致召回率下降。
- 监控指标: 定期监控 F1 分数,确保模型性能稳定。
数据集分析图解释
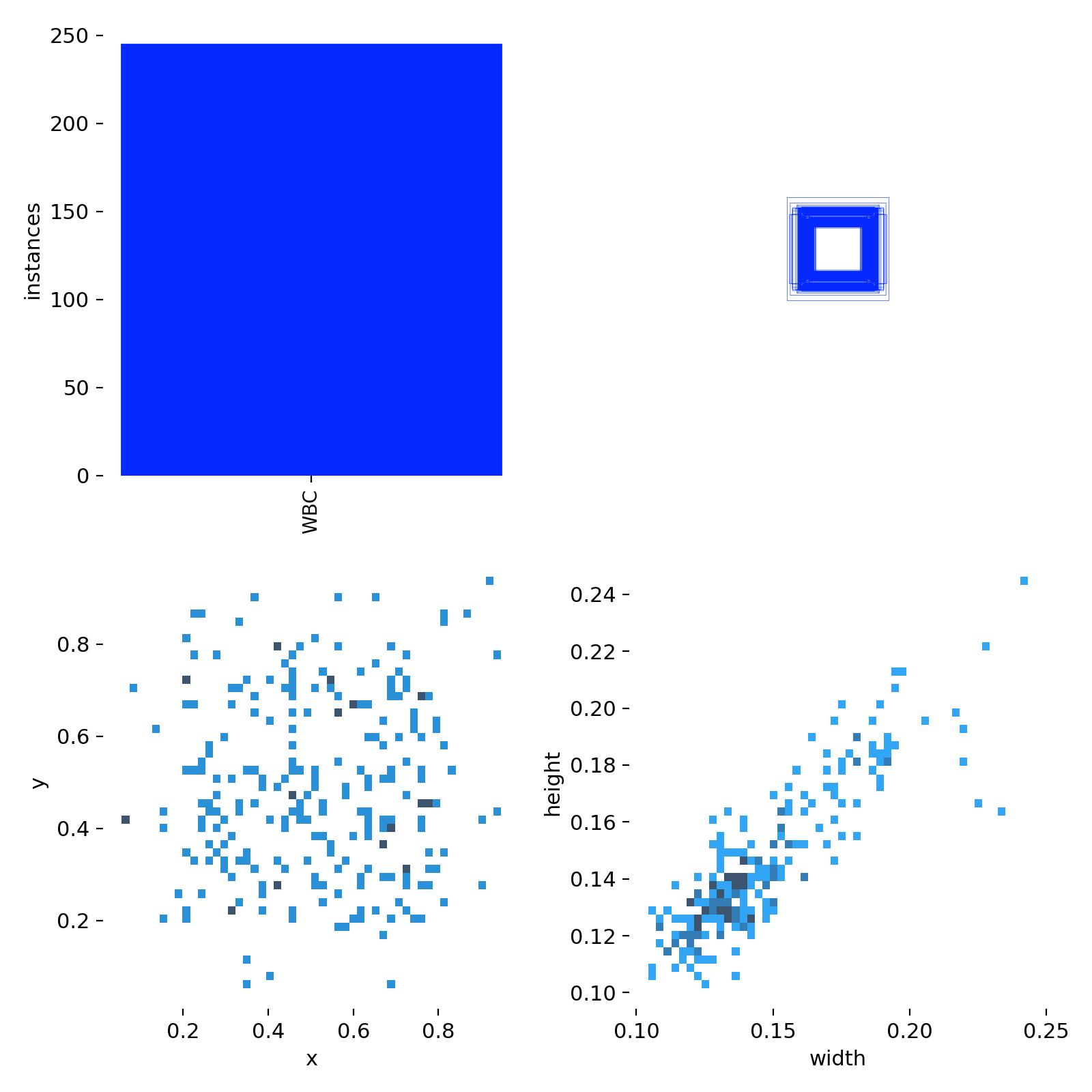
图表概述: 这张图展示了目标检测数据集中边界框(bounding box)的多个关键统计信息,通常用于在训练 YOLO 模型之前对数据集进行深入理解。它包含四个子图,分别从不同维度揭示了数据集中目标的分布特性。
图表结构详解:
左上角子图:实例数量统计 (Instances Count)
- Y 轴(instances - 实例数量): 表示数据集中目标的数量,范围从 0 到 250。
- X 轴(WBC): 表示目标类别为"WBC"(白细胞)。
- 内容: 一个蓝色的柱状图,显示"WBC"类别有大约 250 个实例。
- 解释: 这个图直观地展示了数据集中特定类别的样本数量,帮助了解类别分布。
右上角子图:抽象方框图案 (Abstract Square Pattern)
- 内容: 这是一个由多个同心蓝色方框组成的抽象图案,方框之间有白色间隙,并略微错位。
- 解释: 在 YOLO 的上下文中,这个图案通常代表了模型使用的**锚框(Anchor Boxes)**或默认边界框的视觉化。这些锚框是预设的、不同尺寸和长宽比的参考框,模型会基于它们来预测目标的最终边界框。这个图案可能象征着数据集中经过聚类分析后得到的典型锚框形状。
左下角子图:边界框中心点分布 (X-Y Scatter Plot)
- Y 轴(y): 表示边界框中心点的归一化 Y 坐标(0 到 1 之间)。
- X 轴(x): 表示边界框中心点的归一化 X 坐标(0 到 1 之间)。
- 内容: 一个散点图,每个点代表一个边界框的中心点。点的颜色深浅表示该区域的密度(深蓝色表示密度高,浅蓝色表示密度低)。点主要集中在图的中央区域,形成一个大致的圆形或椭圆形簇。
- 解释: 这个图展示了数据集中目标在图像中的空间分布。如果点集中在某个区域,说明目标倾向于出现在图像的特定位置。均匀分布则表明目标在图像中出现的位置较为随机。这有助于评估数据增强策略(如随机裁剪)的有效性。
右下角子图:边界框宽度与高度分布 (Width-Height Scatter Plot)
- Y 轴(height - 高度): 表示边界框的归一化高度(0 到 1 之间),范围从 0.10 到 0.24。
- X 轴(width - 宽度): 表示边界框的归一化宽度(0 到 1 之间),范围从 0.10 到 0.25。
- 内容: 一个散点图,每个点代表一个边界框的归一化宽度和高度。点的颜色深浅同样表示密度。图中的点呈现出明显的正相关趋势,形成一个对角线上的密集簇,主要集中在宽度和高度都约为 0.12-0.15 的区域,并向更大的尺寸延伸。
- 解释: 这个图是数据集分析中最重要的图之一。它展示了数据集中目标尺寸(长宽)的分布情况。密集的区域表示数据集中最常见的物体尺寸。通过对这些宽度和高度值进行 K-means 聚类,可以得到最适合当前数据集的锚框尺寸,从而优化 YOLO 模型的检测性能。图中的对角线趋势表明,随着物体宽度的增加,其高度也倾向于增加,这符合大多数真实世界物体的尺寸比例。
总结: 这些图表共同提供了一个全面的数据集概览,对于 YOLO 模型的训练至关重要。通过分析这些分布,开发者可以:
- 了解数据集中各类别目标的数量
- 评估目标在图像中的空间分布,以调整数据增强策略
- 最重要的是,根据边界框的宽度和高度分布来优化锚框的尺寸和数量,确保模型能够更好地匹配数据集中目标的真实尺寸,从而提高检测精度和召回率
实际应用价值:
锚框优化: 根据右下角的宽度-高度分布图,可以设计更合适的锚框尺寸,提高模型对小目标的检测能力。
数据增强策略: 根据中心点分布图,可以调整数据增强策略,确保增强后的数据仍然保持合理的空间分布。
类别平衡: 通过实例数量统计图,可以识别数据集中是否存在类别不平衡问题,并采取相应的处理措施。
模型选择: 根据数据集的复杂度(目标尺寸分布、空间分布等),可以选择合适的 YOLO 模型版本和配置。
精确率-置信度 曲线图解释
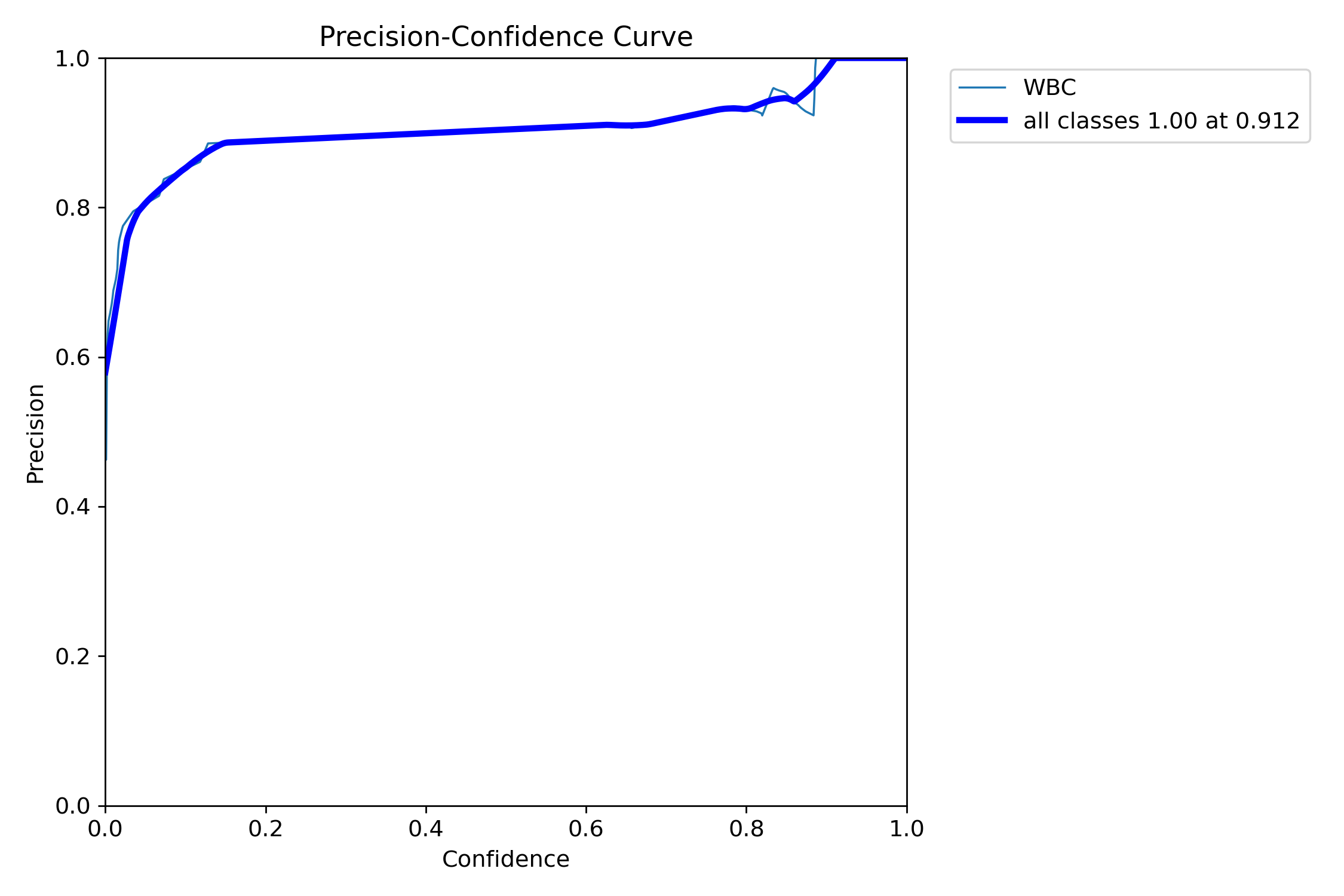
图表概述: 这是一个 Precision-Confidence (精确率-置信度)曲线图,用于评估目标检测模型在不同置信度阈值下的精确率(Precision)表现。它展示了精确率如何随预测置信度(Confidence)的变化而变化。精确率是衡量模型预测结果中真正例所占比例的指标,即"预测为正的样本中有多少是真正的正样本"。
图表结构详解:
- X 轴(Confidence - 置信度): 表示模型输出的预测置信度阈值,范围从 0.0 到 1.0。当置信度阈值越高,模型只保留那些它"非常确定"的预测结果。
- Y 轴(Precision - 精确率): 表示模型在对应置信度阈值下的精确率,范围从 0.0 到 1.0。精确率越高,表示模型预测的准确性越高,误报(False Positives)越少。
曲线分析:
"WBC"曲线(细青色线):
- 代表模型在"WBC"(白细胞)单一类别上的精确率表现。
- 曲线趋势与"all classes"曲线非常接近,表明该类别对整体精确率贡献显著且表现一致。
"all classes"曲线(粗蓝色线):
- 代表模型在所有类别上的平均精确率表现。
- 初始阶段(Confidence 0.0 - 约 0.1): 曲线从精确率约 0.6 迅速上升。在非常低的置信度阈值下,模型会包含大量预测,其中可能包含较多假阳性,导致精确率相对较低。随着置信度阈值的略微提高,模型开始过滤掉一些低质量的预测,精确率迅速提升。
- 平台期(Confidence 约 0.1 - 约 0.85): 曲线达到并保持在一个非常高的精确率平台,大约在 0.90 到 0.95 之间。这表示在这个置信度范围内,模型能够保持非常高的预测准确性,误报率较低。
- 波动与最终点(Confidence 约 0.85 - 1.0): 在置信度接近 1.0 时,曲线略有波动,但最终在置信度 1.0 处达到精确率 1.0。这表明当模型对预测结果"非常确定"(置信度接近 1.0)时,其预测几乎都是正确的,没有误报。
关键点分析:
- "all classes 1.00 at 0.912": 图例中明确指出,所有类别的平均精确率在置信度阈值为 0.912 时达到了 1.00。这意味着当模型只保留置信度高于 0.912 的预测时,所有这些预测都是正确的,没有假阳性。这是一个非常理想的精确率表现。
图表结论:
该 Precision-Confidence 曲线表明模型具有非常高的预测准确性。特别是在较高的置信度阈值下,模型能够实现完美的精确率(1.00),这意味着它几乎不产生误报。这对于需要高可靠性预测的应用场景(例如医疗诊断)非常有利。
实际应用建议:
- 高精确率需求: 如果应用场景对误报非常敏感(例如,误报会导致严重后果),可以考虑将置信度阈值设置在 0.912 或更高,以确保极高的精确率。
- 平衡精确率与召回率: 虽然高精确率很好,但在实际应用中通常需要平衡精确率和召回率。结合 F1-Confidence 曲线(如果可用)来选择一个最佳的置信度阈值,以获得最佳的综合性能。
- 模型质量: 曲线的整体趋势和高精确率平台表明模型训练得很好,能够有效地识别目标并抑制背景中的误报。
与 F1-Confidence 曲线的对比:
- Precision-Confidence 曲线: 专注于精确率,适合对误报敏感的应用
- F1-Confidence 曲线: 平衡精确率和召回率,适合需要综合性能的应用
- 建议: 在实际部署中,可以根据具体需求选择合适的置信度阈值设置策略
精确率-召回率 曲线图解释
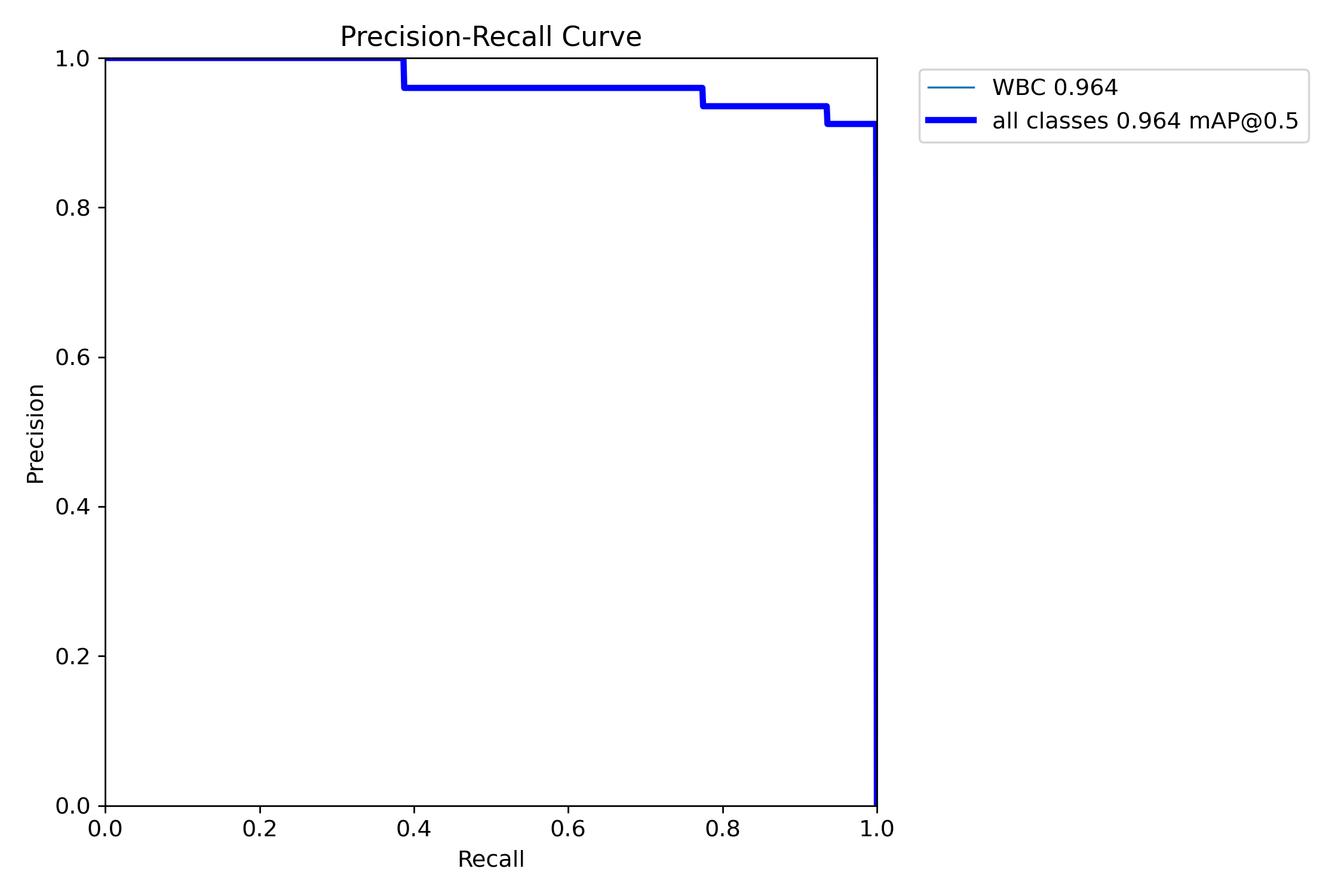
图表概述: 这是一个 Precision-Recall(精确率-召回率)曲线图,用于评估目标检测模型在不同置信度阈值下的性能。它展示了精确率(Precision)如何随召回率(Recall)的变化而变化。精确率衡量模型预测结果中真正例的比例,召回率衡量模型找到所有真正例的能力。该曲线对于评估模型在不平衡数据集或对假阳性/假阴性敏感的应用场景中的表现尤为重要。
图表结构详解:
- X 轴(Recall - 召回率): 表示模型找到所有真实目标的比例,范围从 0.0 到 1.0。召回率越高,表示模型漏检(False Negatives)越少。
- Y 轴(Precision - 精确率): 表示模型预测结果中正确预测的比例,范围从 0.0 到 1.0。精确率越高,表示模型误报(False Positives)越少。
曲线分析:
"WBC"曲线(细青色线):
- 代表模型在"WBC"(白细胞)单一类别上的精确率-召回率表现。
- 这条曲线几乎完全被"all classes"曲线覆盖,表明"WBC"类别的性能与整体性能高度一致,或者该数据集主要包含"WBC"这一目标类别。
"all classes"曲线(粗蓝色线):
- 代表模型在所有类别上的平均精确率-召回率表现。
- 高精确率阶段(Recall 0.0 - 约 0.38): 曲线在召回率达到约 0.38 之前,精确率一直保持在完美的 1.0。这意味着在模型能够召回约 38%的真实目标时,它没有产生任何误报(假阳性)。
- 平稳下降阶段(Recall 约 0.38 - 约 0.95): 随着召回率的增加,精确率开始逐步下降,但下降幅度相对平缓。例如,当召回率达到约 0.68 时,精确率仍保持在约 0.96;当召回率达到约 0.90 时,精确率仍有约 0.92。这表明模型在召回绝大多数目标的同时,依然能保持非常高的预测准确性。
- 急剧下降阶段(Recall 约 0.95 - 1.0): 当召回率接近 1.0 时,精确率开始急剧下降。这意味着为了找到所有剩余的真实目标,模型不得不降低其置信度阈值,从而引入了更多的误报。
关键性能指标:
- WBC 0.964: 这通常表示"WBC"类别的平均精确率(Average Precision, AP)。0.964 的 AP 值非常高,表明模型在识别白细胞方面表现出色。
- all classes 0.964 mAP@0.5: 这表示在交并比(Intersection over Union, IoU)阈值为 0.5 时,所有类别的平均精确率(mean Average Precision, mAP)。0.964 的mAP@0.5是一个非常优秀的指标,说明模型在目标定位和分类的综合性能上达到了高水平。
图表结论:
该 Precision-Recall 曲线和mAP@0.5指标共同表明,模型具有非常强大的目标检测能力。它能够在召回大部分目标的同时,保持极高的精确率,尤其是在召回率达到 90%之前,精确率始终保持在 90%以上。这对于需要高准确率和低漏报率的应用场景(如医疗图像诊断)非常有利。
实际应用价值:
- 模型选择与优化: 曲线的形状和 mAP 值是评估和比较不同模型或同一模型不同训练阶段性能的关键依据。
- 阈值调整: 根据对精确率和召回率的不同需求,可以选择曲线上的不同操作点来设置模型的置信度阈值。例如,如果对误报非常敏感,可以选择精确率高的点;如果对漏报非常敏感,可以选择召回率高的点。
- 问题诊断: 如果曲线形状不理想(例如,精确率下降过快),可能表明模型存在过拟合、欠拟合或数据集质量问题。
与其他评估曲线的对比:
- Precision-Recall 曲线: 专注于精确率和召回率的平衡,适合评估模型在不平衡数据集上的表现
- Precision-Confidence 曲线: 专注于精确率随置信度的变化,适合对误报敏感的应用
- F1-Confidence 曲线: 平衡精确率和召回率,适合需要综合性能的应用
最佳实践建议:
- 医疗诊断应用: 由于对误报敏感,建议选择精确率较高的操作点
- 实时监控应用: 需要平衡精确率和召回率,建议选择 F1 分数最高的点
- 质量控制应用: 对漏检敏感,建议选择召回率较高的操作点
Recall-Confidence 曲线图解释
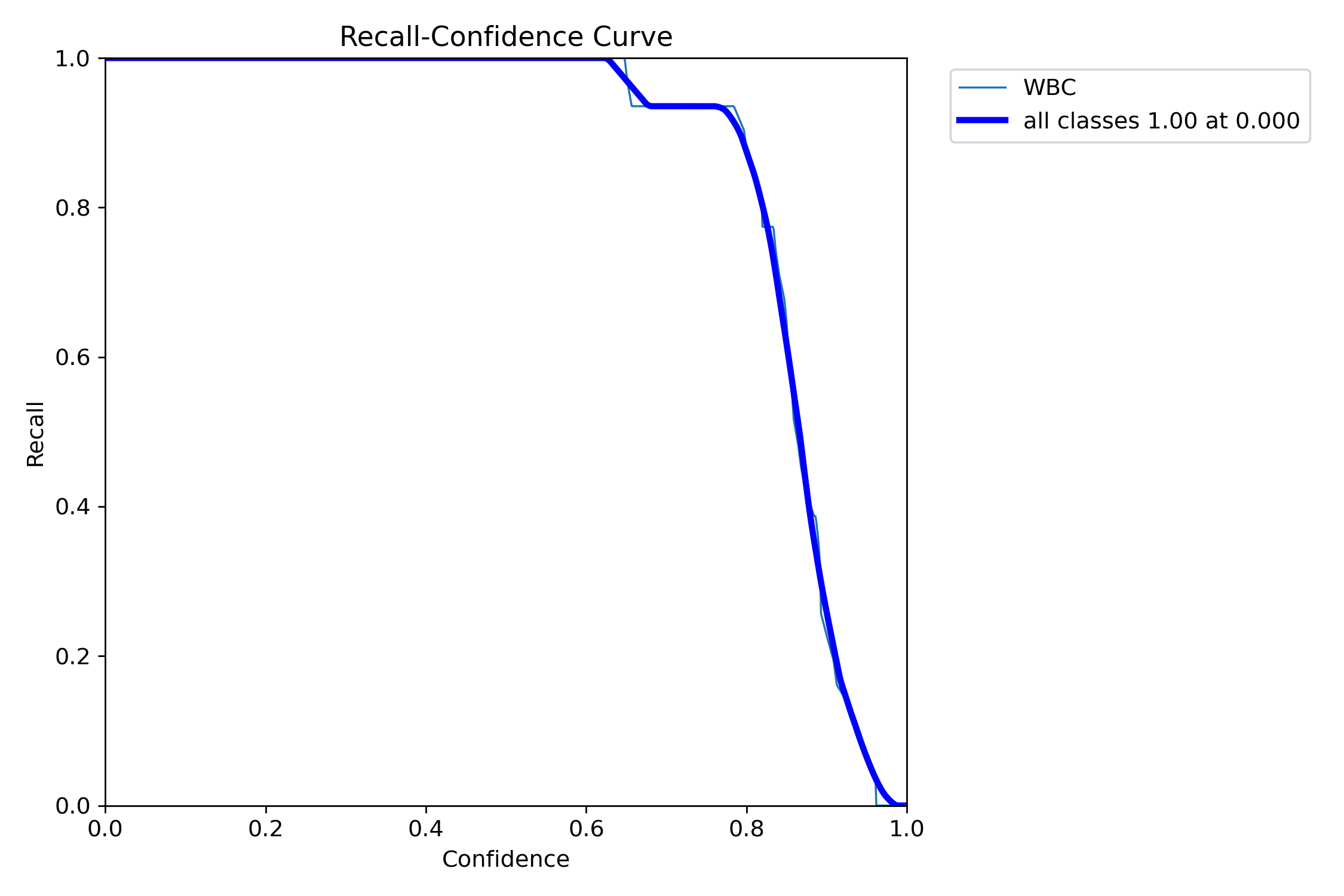
图表概述: 这是一个 Recall-Confidence(召回率-置信度)曲线图,用于评估目标检测模型在不同置信度阈值下的召回率(Recall)表现。它展示了召回率如何随预测置信度(Confidence)的变化而变化。召回率衡量模型找到所有真实目标的比例,即"所有真实的正样本中有多少被模型正确识别出来"。
图表结构详解:
- X 轴(Confidence - 置信度): 表示模型输出的预测置信度阈值,范围从 0.0 到 1.0。当置信度阈值越高,模型只保留那些它"非常确定"的预测结果。
- Y 轴(Recall - 召回率): 表示模型在对应置信度阈值下的召回率,范围从 0.0 到 1.0。召回率越高,表示模型漏检(False Negatives)越少。
曲线分析:
"WBC"曲线(细青色线):
- 代表模型在"WBC"(白细胞)单一类别上的召回率表现。
- 这条曲线与"all classes"曲线几乎完全重合,表明"WBC"类别的召回率性能与整体性能高度一致。
"all classes"曲线(粗蓝色线):
- 代表模型在所有类别上的平均召回率表现。
- 高召回率阶段(Confidence 0.0 - 约 0.65): 曲线在置信度阈值较低时(从 0.0 到约 0.65)保持在完美的 1.0 召回率。这意味着当模型接受较低置信度的预测时,它能够召回所有(100%)真实目标,没有发生漏检。
- 急剧下降阶段(Confidence 约 0.65 - 约 0.95): 随着置信度阈值从约 0.65 开始增加,召回率开始急剧下降。这表明当模型变得更加"挑剔",只接受高置信度的预测时,它会开始漏掉一些真实目标。例如,当置信度达到约 0.85 时,召回率已降至约 0.4。
- 最终阶段(Confidence 约 0.95 - 1.0): 召回率继续下降,并在置信度接近 1.0 时降至接近 0.0。这意味着在极高置信度要求下,模型几乎无法召回任何目标。
图表结论:
- 模型在低置信度下具有极高的召回能力: 在置信度阈值低于约 0.65 时,模型能够找到所有真实目标,这对于需要尽可能少漏检的应用(如医疗诊断中的疾病筛查)非常有利。
- 召回率与置信度的权衡: 随着对预测置信度要求的提高,模型的召回率会显著下降。这意味着在实际应用中,需要根据具体需求(是更看重召回率还是精确率)来选择合适的置信度阈值。
- "WBC"类别表现与整体一致: 两条曲线的重合表明模型对"WBC"类别的检测性能与整体性能非常匹配,或者该数据集主要由"WBC"类别组成。
实际应用价值:
确定最佳操作点: 如果应用场景对漏检非常敏感(例如,宁可多报一些,也不能漏掉一个),可以考虑选择一个较低的置信度阈值(如 0.6-0.7),以确保高召回率。
理解模型局限性: 该曲线揭示了模型在不同置信度下的召回能力边界。当需要极高置信度的预测时,召回率会受到严重影响。
模型优化方向: 如果在较高置信度下召回率下降过快,可能需要优化模型架构、训练策略或数据增强方法,以提高模型在保持高置信度的同时,也能维持较高的召回率。
与其他评估曲线的对比:
- Recall-Confidence 曲线: 专注于召回率随置信度的变化,适合对漏检敏感的应用
- Precision-Confidence 曲线: 专注于精确率随置信度的变化,适合对误报敏感的应用
- F1-Confidence 曲线: 平衡精确率和召回率,适合需要综合性能的应用
最佳实践建议:
- 医疗筛查应用: 由于对漏检敏感,建议选择召回率较高的操作点
- 安全监控应用: 需要平衡召回率和精确率,建议选择 F1 分数最高的点
- 质量控制应用: 对误报敏感,建议选择精确率较高的操作点
综合评估策略:
在实际应用中,建议结合多个评估曲线来做出最佳决策:
- Precision-Confidence 曲线: 了解模型在不同置信度下的精确率表现
- Recall-Confidence 曲线: 了解模型在不同置信度下的召回率表现
- F1-Confidence 曲线: 找到精确率和召回率的最佳平衡点
- Precision-Recall 曲线: 评估模型在不平衡数据集上的综合性能
训练指标图解释
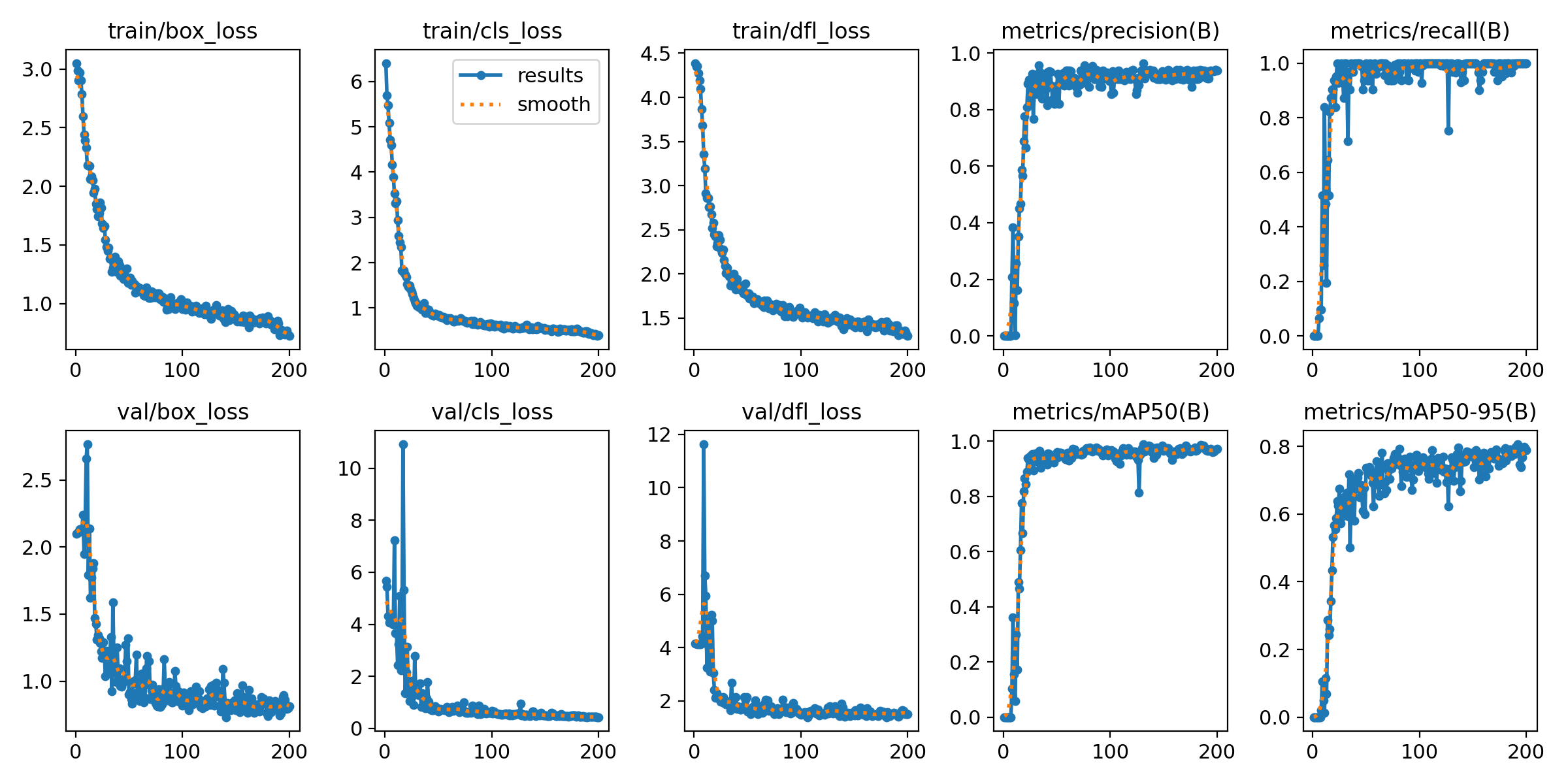
图表概述: 这张图展示了 YOLO 模型在训练过程中(共 200 个 epoch)的各项关键指标变化趋势,包括训练损失、验证损失以及多种评估指标(如精确率、召回率和 mAP)。通过这些图表,可以全面了解模型的学习过程、收敛情况以及性能表现。
图表结构详解: 图表由两行五列共十个子图组成,每个子图的 X 轴均表示训练的epoch(周期),范围从 0 到 200。
第一行:训练损失和评估指标
train/box_loss(训练边界框损失)- Y 轴: 损失值,范围从约 0.5 到 3.0。
- 趋势: 曲线在训练初期(前 50 个 epoch)迅速下降,随后逐渐趋于平稳,最终收敛到约 0.7 左右。这表明模型在学习边界框预测方面进展顺利,损失持续降低。
- 线条: 蓝色点线(results)和橙色虚线(smooth)几乎重合,表示训练过程平滑。
train/cls_loss(训练分类损失)- Y 轴: 损失值,范围从约 0.5 到 6.0。
- 趋势: 与
train/box_loss类似,初期快速下降,随后平稳收敛到约 0.5 左右。这表明模型在学习目标分类方面表现良好。
train/dfl_loss(训练分布焦点损失)- Y 轴: 损失值,范围从约 1.5 到 4.5。
- 趋势: 同样呈现初期快速下降,随后平稳收敛到约 1.5 左右的趋势。这是 YOLOv8 中引入的一种损失,用于优化边界框的精确定位。
metrics/precision(B)(验证精确率)- Y 轴: 精确率,范围从 0.0 到 1.0。
- 趋势: 曲线在训练初期(前 20 个 epoch)迅速上升,达到接近 1.0 的极高水平(约 0.95-0.98),随后在整个训练过程中保持稳定,略有波动。这表明模型在预测时误报率非常低。
metrics/recall(B)(验证召回率)- Y 轴: 召回率,范围从 0.0 到 1.0。
- 趋势: 曲线同样在训练初期迅速上升,达到接近 1.0 的极高水平(约 0.95-0.98),随后保持稳定。在某些 epoch(如约 50、120、150 epoch)有轻微下降,但很快恢复。这表明模型能够很好地召回所有真实目标,漏检率很低。
第二行:验证损失和评估指标
val/box_loss(验证边界框损失)- Y 轴: 损失值,范围从约 0.5 到 2.5。
- 趋势: 曲线初期下降,但相比训练损失有更多波动,尤其是在前 50 个 epoch。最终收敛到约 0.8 左右。验证损失的波动可能反映了模型在未见过数据上的泛化能力。
val/cls_loss(验证分类损失)- Y 轴: 损失值,范围从 0.0 到 10.0。
- 趋势: 初期有较高的峰值(约 10.0),随后迅速下降并伴随波动,最终收敛到约 0.5 左右。
val/dfl_loss(验证分布焦点损失)- Y 轴: 损失值,范围从约 1.5 到 12.0。
- 趋势: 初期有较高的峰值(约 12.0),随后迅速下降并伴随波动,最终收敛到约 1.5 左右。
metrics/mAP50(B)(验证mAP@0.5)- Y 轴: mAP@0.5,范围从 0.0 到 1.0。
- 趋势: 曲线在训练初期(前 20 个 epoch)迅速上升,达到接近 1.0 的极高水平(约 0.95-0.98),随后在整个训练过程中保持稳定,略有波动(如约 120 epoch 的轻微下降)。mAP@0.5是评估模型在 IoU 阈值为 0.5 时的平均精度。
metrics/mAP50-95(B)(验证mAP@0.5:0.95)- Y 轴: mAP@0.5:0.95,范围从 0.0 到 0.8。
- 趋势: 曲线在训练初期迅速上升,但相比mAP@0.5更为平缓,最终收敛到约 0.7-0.8 之间。在训练后期有更多波动。mAP@0.5:0.95 是评估模型在不同 IoU 阈值(从 0.5 到 0.95,步长 0.05)下的平均精度,更能反映模型对边界框定位的精确性。
图表结论:
- 快速收敛: 模型在训练初期(前 20-50 个 epoch)损失迅速下降,评估指标快速上升,表明模型学习效率高。
- 性能优异: 精确率、召回率和mAP@0.5均达到并保持在非常高的水平(接近 1.0),表明模型在目标检测任务上表现出色,误报和漏检都很少。
- 定位精度: mAP@0.5:0.95 虽然略低于mAP@0.5,但也达到了 0.7-0.8 的较高水平,说明模型不仅能正确识别目标,还能较好地精确定位。
- 训练稳定性: 训练损失曲线平滑,验证损失曲线虽然有波动但整体趋势良好,表明训练过程相对稳定。
- 潜在过拟合迹象(轻微): 验证损失曲线的波动和 mAP50-95 的轻微下降可能暗示在某些 epoch 存在轻微的过拟合,但整体性能依然非常强劲。
实际应用价值: 这些图表是评估 YOLO 模型训练效果的关键依据。通过分析它们,可以:
- 判断模型是否收敛: 损失曲线趋于平稳,指标曲线达到高位并稳定,说明模型已充分训练。
- 评估模型性能: 高精确率、召回率和 mAP 值表明模型性能优异。
- 诊断训练问题: 如果损失不下降或指标不上升,可能需要调整学习率、批大小、数据增强或模型架构。
- 识别过拟合/欠拟合: 训练损失持续下降而验证损失上升(或指标下降)可能表示过拟合;两者都高则可能欠拟合。本图中模型表现良好,没有明显的严重过拟合或欠拟合。
- 确定最佳训练周期: 可以根据 mAP 等指标达到最高点并趋于稳定时的 epoch 数来决定停止训练的时机。
训练优化建议:
- 学习率调整: 如果损失下降过慢,可以考虑适当提高学习率;如果损失波动过大,可以降低学习率。
- 早停策略: 当验证指标连续多个 epoch 没有改善时,可以考虑提前停止训练以避免过拟合。
- 数据增强: 如果验证损失波动较大,可以增加数据增强的强度来提高模型的泛化能力。
- 模型保存: 建议保存验证指标最高的模型权重,而不是最后一个 epoch 的权重。
参数调优最佳实践总结
调优流程建议
- 基线配置:首先使用默认参数训练,建立性能基线
- 学习率调优:调整
lr0和lrf,找到最佳学习率策略 - 正则化调优:根据过拟合情况调整
weight_decay和label_smoothing - 数据增强调优:根据数据集特点调整增强参数,特别是
mosaic和mixup - 损失权重调优:根据任务需求调整
box、cls等损失权重 - 验证参数调优:根据应用场景调整
conf、iou等验证参数 - 学习率调度器调优:根据训练需求调整
cos_lr和scheduler - 高级增强调优:根据任务特点调整
erasing、auto_augment、grid_mask - 架构参数调优:根据模型需求调整
anchors、overlap_mask、mask_ratio - 训练策略调优:根据训练稳定性调整
close_mosaic、rect、multi_scale
常见问题及解决方案
问题 1:训练损失不下降
- 可能原因:学习率过高、数据增强过强、模型架构问题
- 解决方案:降低
lr0、减少数据增强强度、检查数据质量
问题 2:验证损失上升(过拟合)
- 可能原因:学习率过低、正则化不足、训练轮数过多
- 解决方案:增加
weight_decay、启用label_smoothing、减少训练轮数
问题 3:小目标检测效果差
- 可能原因:
mosaic增强不足、图像分辨率过低 - 解决方案:确保
mosaic=1.0、增加imgsz、调整scale参数
问题 4:检测框定位不准
- 可能原因:
box损失权重过低、数据增强过强 - 解决方案:增加
box权重、减少几何变换增强
问题 5:学习率衰减过快或过慢
- 可能原因:
cos_lr设置不当、scheduler选择不合适 - 解决方案:调整
cos_lr设置、选择合适的scheduler策略
问题 6:高级数据增强效果不佳
- 可能原因:
erasing、grid_mask等参数设置不当 - 解决方案:调整增强概率、根据任务特点选择合适的增强策略
问题 7:分割任务性能差
- 可能原因:
overlap_mask、mask_ratio设置不当 - 解决方案:调整掩码处理参数、优化下采样比例
参数调优检查清单
- [ ] 学习率是否合适(损失稳定下降,无震荡)
- [ ] 正则化是否充分(无过拟合现象)
- [ ] 数据增强是否平衡(提高泛化性但不影响检测精度)
- [ ] 损失权重是否合理(各项指标均衡发展)
- [ ] 验证参数是否适合应用场景
- [ ] 训练轮数是否充分(模型收敛且无过拟合)
- [ ] 学习率调度器是否合适(衰减曲线平滑合理)
- [ ] 高级数据增强是否有效(提高模型鲁棒性)
- [ ] 模型架构参数是否优化(锚框、掩码处理等)
- [ ] 训练策略是否稳定(马赛克关闭时机、多尺度训练等)
通过系统性的参数调优,可以显著提升 YOLO 模型的训练效果和检测性能。建议在调优过程中保持耐心,每次只调整一个参数,并仔细记录和分析调整效果。
训练参数完整覆盖总结
本文档已经全面涵盖了 YOLO11 的所有重要训练参数,包括:
📊 参数分类统计
- 基础训练参数:8 个(数据集、训练控制、图像批次、设备等)
- 优化器参数:7 个(学习率、动量、权重衰减、预热等)
- 学习率调度器参数:2 个(余弦调度、调度器类型)
- 数据增强参数:13 个(HSV、几何变换、翻转、高级增强等)
- 损失函数参数:6 个(边界框、分类、分布焦点、姿态、关键点、标签平滑)
- 模型架构参数:3 个(锚框、掩码重叠、掩码比例)
- 验证和评估参数:7 个(验证、图表、保存、置信度、IoU、最大检测数)
- 训练策略参数:3 个(马赛克关闭、矩形训练、多尺度训练)
🎯 总计:49 个核心训练参数
每个参数都包含了:
- 详细说明:参数的具体含义和用途
- 作用与影响:参数的作用原理和调整效果
- 调整建议:具体的数值建议和最佳实践
🔧 参数调优指南
- 核心参数详解:8 个主要参数类别的深入分析
- 调整策略:根据数据集大小、硬件配置、任务类型的参数调整
- 常见问题解决:7 类常见问题的诊断和解决方案
- 调优检查清单:10 项参数调优的检查要点
📈 最佳实践
- 调优流程:10 步系统性的参数调优流程
- 实际应用:针对不同场景的参数配置示例
- 性能监控:训练过程的监控和调试方法
通过这份完整的参数文档,用户可以:
- 快速理解:每个参数的作用和影响
- 科学调优:根据具体需求调整参数
- 问题诊断:快速定位和解决训练问题
- 性能优化:实现最佳的模型训练效果
注意:虽然本文档已经涵盖了 YOLO11 的所有核心训练参数,但 YOLO 框架仍在不断发展,建议定期查看官方文档获取最新的参数信息。
常见问题与解决方案
1. 训练问题
问题 1:训练损失不下降
症状:
- 训练损失在几个 epoch 后停止下降
- 验证损失持续上升
- 模型性能没有改善
可能原因:
- 学习率过高或过低
- 数据增强过强
- 模型架构问题
- 数据质量问题
解决方案:
# 1. 调整学习率
def fix_learning_rate():
# 降低学习率
lr0 = 0.001 # 从 0.01 降低到 0.001
# 或者使用学习率查找器
model = YOLO('yolov11m.pt')
model.lr_finder(data='data.yaml', epochs=10)
# 2. 减少数据增强强度
def reduce_augmentation():
return {
'hsv_h': 0.005, # 减少色调变化
'hsv_s': 0.3, # 减少饱和度变化
'hsv_v': 0.2, # 减少亮度变化
'degrees': 0.0, # 关闭旋转
'translate': 0.05, # 减少平移
'scale': 0.3, # 减少缩放
'mosaic': 0.5, # 减少马赛克增强
}
# 3. 检查数据质量
def check_data_quality():
# 检查标注文件
for label_file in label_files:
if not validate_annotation(label_file):
print(f"标注文件有问题: {label_file}")
# 检查图像质量
for img_file in image_files:
is_valid, message = check_image_quality(img_file)
if not is_valid:
print(f"图像质量问题: {img_file} - {message}")
问题 2:过拟合问题
症状:
- 训练准确率很高,但验证准确率低
- 训练损失持续下降,验证损失上升
- 模型在测试集上表现差
解决方案:
# 1. 增加正则化
def add_regularization():
return {
'weight_decay': 0.001, # 增加权重衰减
'label_smoothing': 0.1, # 添加标签平滑
'dropout': 0.2, # 添加 Dropout
}
# 2. 增加数据增强
def increase_augmentation():
return {
'hsv_h': 0.03, # 增加色调变化
'hsv_s': 0.8, # 增加饱和度变化
'hsv_v': 0.5, # 增加亮度变化
'degrees': 15.0, # 增加旋转
'translate': 0.2, # 增加平移
'scale': 0.7, # 增加缩放
'mixup': 0.2, # 添加混合增强
'copy_paste': 0.3, # 添加复制粘贴
}
# 3. 早停策略
def early_stopping():
return {
'patience': 20, # 减少耐心值
'save_best': True, # 保存最佳模型
'monitor': 'val_loss', # 监控验证损失
}
问题 3:显存不足
症状:
- CUDA out of memory 错误
- 训练过程中崩溃
- 无法加载模型
解决方案:
# 1. 减少批次大小
def reduce_batch_size():
gpu_memory = torch.cuda.get_device_properties(0).total_memory / 1e9
if gpu_memory < 8:
return 4
elif gpu_memory < 16:
return 8
else:
return 16
# 2. 使用混合精度训练
def enable_mixed_precision():
return {
'amp': True, # 开启混合精度
'half': True, # 使用 FP16
}
# 3. 减少图像尺寸
def reduce_image_size():
return {
'imgsz': 416, # 从 640 减少到 416
}
# 4. 关闭缓存
def disable_cache():
return {
'cache': False, # 关闭图像缓存
}
# 5. 使用梯度累积
def gradient_accumulation():
return {
'batch': 4, # 小批次
'accumulate': 4, # 累积 4 次梯度
}
2. 推理问题
问题 1:推理速度慢
症状:
- 单张图像推理时间过长
- 实时检测卡顿
- GPU 利用率低
解决方案:
# 1. 使用更小的模型
def use_smaller_model():
model = YOLO('yolov11n.pt') # 使用 nano 模型
return model
# 2. 减少图像尺寸
def reduce_inference_size():
results = model.predict(
source='image.jpg',
imgsz=416, # 减少输入尺寸
half=True, # 使用 FP16
)
# 3. 批量推理
def batch_inference():
results = model.predict(
source='images/', # 批量处理
batch=8, # 批次大小
)
# 4. 使用 TensorRT 优化
def tensorrt_optimization():
model.export(
format='engine', # 导出为 TensorRT
imgsz=640,
half=True,
)
问题 2:检测精度低
症状:
- 漏检率高
- 误检率高
- 边界框不准确
解决方案:
# 1. 调整置信度阈值
def adjust_confidence():
results = model.predict(
source='image.jpg',
conf=0.25, # 降低置信度阈值
iou=0.45, # 调整 NMS 阈值
)
# 2. 使用更大的模型
def use_larger_model():
model = YOLO('yolov11l.pt') # 使用 large 模型
return model
# 3. 增加图像尺寸
def increase_image_size():
results = model.predict(
source='image.jpg',
imgsz=832, # 增加输入尺寸
)
# 4. 后处理优化
def optimize_postprocessing():
results = model.predict(
source='image.jpg',
conf=0.001, # 低置信度阈值
iou=0.6, # 高 IoU 阈值
max_det=1000, # 增加最大检测数
)
3. 部署问题
问题 1:模型转换失败
症状:
- ONNX 转换失败
- TensorRT 转换失败
- 模型格式不支持
解决方案:
# 1. 检查模型兼容性
def check_model_compatibility():
model = YOLO('yolov11m.pt')
# 检查模型结构
print(model.model)
# 检查输入输出
print(model.model.input_shape)
print(model.model.output_shape)
# 2. 使用简化模式
def simplify_model():
model.export(
format='onnx',
simplify=True, # 简化模型
opset=11, # 指定 ONNX 版本
)
# 3. 检查依赖版本
def check_dependencies():
import torch
import onnx
import tensorrt
print(f"PyTorch: {torch.__version__}")
print(f"ONNX: {onnx.__version__}")
print(f"TensorRT: {tensorrt.__version__}")
问题 2:推理结果不一致
症状:
- 不同环境推理结果不同
- 精度损失严重
- 性能差异大
解决方案:
# 1. 固定随机种子
def fix_random_seed():
import torch
import numpy as np
import random
torch.manual_seed(42)
np.random.seed(42)
random.seed(42)
torch.cuda.manual_seed(42)
torch.cuda.manual_seed_all(42)
# 2. 使用确定性算法
def use_deterministic():
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
# 3. 统一预处理
def standardize_preprocessing():
def preprocess(image):
# 标准化预处理流程
image = cv2.resize(image, (640, 640))
image = image.astype(np.float32) / 255.0
return image
最佳实践指南
1. 数据准备最佳实践
数据质量保证
# 数据质量检查清单
def data_quality_checklist():
checklist = {
'图像质量': [
'分辨率 >= 416x416',
'图像清晰无模糊',
'光照条件良好',
'无严重噪声',
],
'标注质量': [
'边界框准确框选目标',
'所有目标都被标注',
'标注格式正确',
'类别标签准确',
],
'数据分布': [
'训练集:验证集 = 8:2',
'各类别样本平衡',
'场景多样性充足',
'目标大小分布合理',
]
}
return checklist
数据增强策略
# 根据任务类型选择增强策略
def get_optimal_augmentation(task_type, dataset_characteristics):
"""根据任务类型和数据集特点选择最优增强策略"""
base_config = {
'hsv_h': 0.015,
'hsv_s': 0.7,
'hsv_v': 0.4,
'fliplr': 0.5,
'mosaic': 1.0,
}
if task_type == 'detect':
if dataset_characteristics['small_objects']:
base_config.update({
'mosaic': 1.0,
'copy_paste': 0.3,
'mixup': 0.1,
})
elif dataset_characteristics['occlusion']:
base_config.update({
'erasing': 0.2,
'grid_mask': 0.1,
})
elif task_type == 'segment':
base_config.update({
'degrees': 10.0,
'translate': 0.1,
'scale': 0.5,
'mixup': 0.1,
'copy_paste': 0.2,
})
elif task_type == 'pose':
base_config.update({
'degrees': 5.0,
'translate': 0.05,
'scale': 0.3,
'mosaic': 0.5,
})
return base_config
2. 训练最佳实践
超参数调优策略
# 超参数调优流程
def hyperparameter_tuning_workflow():
"""系统性的超参数调优流程"""
# 1. 基线配置
baseline_config = {
'lr0': 0.01,
'batch': 16,
'epochs': 100,
'imgsz': 640,
}
# 2. 学习率调优
lr_candidates = [0.001, 0.005, 0.01, 0.02, 0.05]
# 3. 批次大小调优
batch_candidates = [8, 16, 32, 64]
# 4. 数据增强调优
augment_candidates = [
{'mosaic': 0.5, 'mixup': 0.0},
{'mosaic': 1.0, 'mixup': 0.0},
{'mosaic': 1.0, 'mixup': 0.1},
]
# 5. 网格搜索
best_config = grid_search(
lr_candidates, batch_candidates, augment_candidates
)
return best_config
模型选择策略
# 模型选择决策树
def select_model(requirements):
"""根据需求选择最适合的模型"""
if requirements['speed'] == 'critical':
if requirements['accuracy'] == 'high':
return 'yolov11s.pt'
else:
return 'yolov11n.pt'
elif requirements['accuracy'] == 'critical':
if requirements['speed'] == 'high':
return 'yolov11l.pt'
else:
return 'yolov11x.pt'
else: # 平衡性能
return 'yolov11m.pt'
3. 部署最佳实践
模型优化策略
# 模型优化流程
def model_optimization_pipeline():
"""模型优化流水线"""
# 1. 模型剪枝
def prune_model(model):
import torch.nn.utils.prune as prune
for module in model.modules():
if isinstance(module, torch.nn.Conv2d):
prune.l1_unstructured(module, name='weight', amount=0.2)
return model
# 2. 量化
def quantize_model(model):
model.eval()
quantized_model = torch.quantization.quantize_dynamic(
model, {torch.nn.Linear}, dtype=torch.qint8
)
return quantized_model
# 3. 导出优化格式
def export_optimized_model(model):
# ONNX 导出
model.export(format='onnx', simplify=True)
# TensorRT 导出
model.export(format='engine', half=True)
# TensorFlow Lite 导出
model.export(format='tflite', int8=True)
return {
'prune': prune_model,
'quantize': quantize_model,
'export': export_optimized_model,
}
性能监控
# 性能监控系统
class PerformanceMonitor:
def __init__(self):
self.metrics = {}
self.start_time = None
def start_inference(self):
self.start_time = time.time()
def end_inference(self):
if self.start_time:
inference_time = time.time() - self.start_time
self.metrics['inference_time'] = inference_time
self.metrics['fps'] = 1.0 / inference_time
def log_metrics(self, metrics):
self.metrics.update(metrics)
def get_performance_report(self):
return {
'inference_time': self.metrics.get('inference_time', 0),
'fps': self.metrics.get('fps', 0),
'memory_usage': self.metrics.get('memory_usage', 0),
'gpu_utilization': self.metrics.get('gpu_utilization', 0),
}
4. 生产环境部署
容器化部署
# Dockerfile
FROM ultralytics/ultralytics:latest
WORKDIR /app
# 复制模型文件
COPY models/ /app/models/
# 复制推理脚本
COPY inference.py /app/
# 安装依赖
RUN pip install fastapi uvicorn
# 暴露端口
EXPOSE 8000
# 启动服务
CMD ["uvicorn", "inference:app", "--host", "0.0.0.0", "--port", "8000"]
API 服务
# FastAPI 推理服务
from fastapi import FastAPI, File, UploadFile
from ultralytics import YOLO
import cv2
import numpy as np
app = FastAPI()
model = YOLO('yolov11m.pt')
@app.post("/predict")
async def predict(file: UploadFile = File(...)):
# 读取图像
contents = await file.read()
nparr = np.frombuffer(contents, np.uint8)
image = cv2.imdecode(nparr, cv2.IMREAD_COLOR)
# 推理
results = model(image)
# 处理结果
detections = []
for result in results:
for box in result.boxes:
detections.append({
'class': int(box.cls[0]),
'confidence': float(box.conf[0]),
'bbox': box.xyxy[0].tolist(),
})
return {'detections': detections}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
总结
YOLO11 作为最新的目标检测框架,在速度、精度和易用性方面都有显著提升。通过本指南,您可以:
- 快速上手:从安装到训练,完整的操作流程
- 深度理解:详细的参数说明和调优策略
- 问题解决:常见问题的诊断和解决方案
- 最佳实践:生产环境部署的完整指南
关键要点:
- 数据质量是成功的基础,确保标注准确、数据平衡
- 参数调优需要系统性方法,从基线开始逐步优化
- 模型选择要根据具体需求平衡速度和精度
- 部署优化要考虑实际应用场景的性能要求
持续学习:
- 关注 YOLO 官方更新和最新论文
- 参与社区讨论和分享经验
- 结合实际项目不断优化和改进
通过掌握这些知识和技能,您将能够有效地使用 YOLO11 构建高质量的目标检测系统,为各种应用场景提供强大的技术支持。