
Redis cluster 数据分片(crc16 哈希算法)
1. 什么是数据分片
在 Redis 的 Cluster 集群模式中,使用了哈希槽(hash slot)的方式来进行数据分片,将整个数据集划分为 16384 个槽,每个节点负责部分槽。客户端访问数据时,先计算出数据对应的槽,然后直接连接到该槽所在的节点进行操作,如下图:
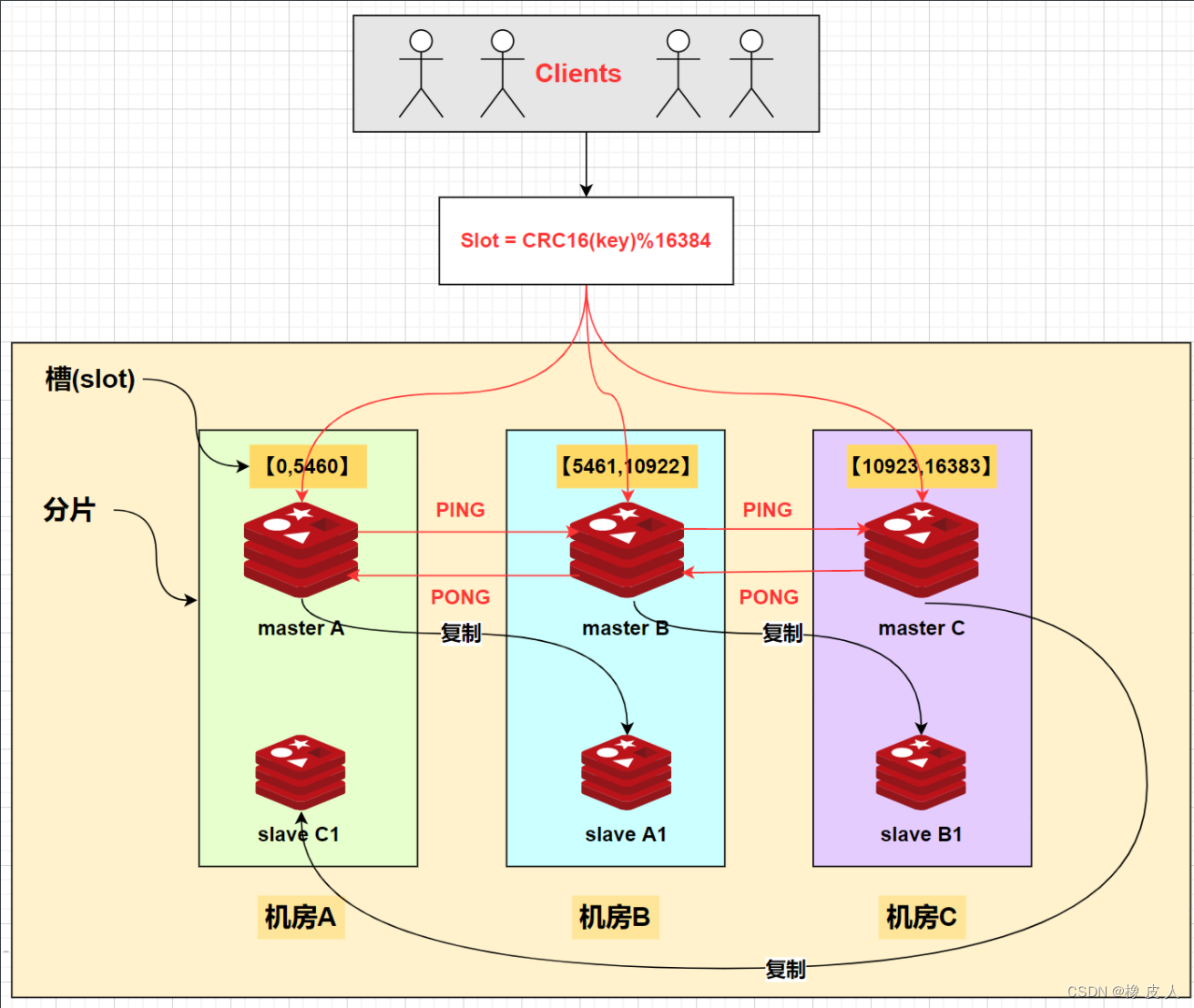
当我们存取 key 的时候,Redis 会根据 CRC16 算法得出一个结果,然后把结果对 16384 取模,这样就得到了一个在 0~16384 范围之间的哈希槽,通过这个值,去找到对应负责该槽的节点,然后就可以进行存取操作了。
2. Redis 节点的增加和删除
无论是增加还是删除节点,redis cluster 都会让数据尽可能的均匀分布。比如,现在有三个节点:Redis1[0,5460],Redis2[5461,10922],Redis3[10924,16383]。
- 这时增加了一台 Redis4,那么 cluster 就会从 1、2、3 的数据会迁移一部分到节点 4 上,实现 4 个节点数据均匀,这时每个节点的负责 16384/4 = 4096 个槽。
- 减少节点也同理,假设删除 Redis,那么 Redis4 节点上数据也会均匀地迁移到 1、2、3,删除后,现在每个节点负责的槽位是:16384/3=6128。
3. Redis Cluster 的分片实现(CRC16 哈希算法)
3.1 CRC16 算法原理
CRC16(Cyclic Redundancy Check)是一种循环冗余校验算法,Redis Cluster 使用 CRC16 算法来计算键的哈希值。具体实现如下:
public class CRC16 {
private static final int[] CRC16_TABLE = new int[256];
static {
for (int i = 0; i < 256; i++) {
int crc = i;
for (int j = 0; j < 8; j++) {
if ((crc & 1) == 1) {
crc = (crc >>> 1) ^ 0xA001;
} else {
crc = crc >>> 1;
}
}
CRC16_TABLE[i] = crc;
}
}
public static int getCRC16(String key) {
int crc = 0;
for (byte b : key.getBytes()) {
crc = ((crc << 8) & 0xFF00) ^ CRC16_TABLE[((crc >> 8) ^ b) & 0xFF];
}
return crc & 0xFFFF;
}
public static int getSlot(String key) {
return getCRC16(key) % 16384;
}
}
3.2 哈希槽分配过程
计算哈希值:
- 对键名进行 CRC16 计算
- 得到 16 位的哈希值(0-65535)
计算槽位:
- 将哈希值对 16384 取模
- 得到 0-16383 之间的槽位号
查找节点:
- 根据槽位号找到负责该槽位的节点
- 将请求转发到对应节点
3.3 SpringBoot 集成 Redis Cluster 示例
3.3.1 添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
3.3.2 配置文件
spring:
redis:
cluster:
nodes:
- 127.0.0.1:7001
- 127.0.0.1:7002
- 127.0.0.1:7003
- 127.0.0.1:7004
- 127.0.0.1:7005
- 127.0.0.1:7006
max-redirects: 3
timeout: 6000
lettuce:
pool:
max-active: 8
max-wait: -1
max-idle: 8
min-idle: 0
3.3.3 配置类
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory connectionFactory) {
RedisTemplate<String, Object> template = new RedisTemplate<>();
template.setConnectionFactory(connectionFactory);
// 设置key的序列化方式
template.setKeySerializer(new StringRedisSerializer());
// 设置value的序列化方式
template.setValueSerializer(new GenericJackson2JsonRedisSerializer());
// 设置hash key的序列化方式
template.setHashKeySerializer(new StringRedisSerializer());
// 设置hash value的序列化方式
template.setHashValueSerializer(new GenericJackson2JsonRedisSerializer());
template.afterPropertiesSet();
return template;
}
}
3.3.4 使用示例
@Service
public class UserService {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
// 存储用户信息
public void saveUser(User user) {
String key = "user:" + user.getId();
redisTemplate.opsForValue().set(key, user);
}
// 获取用户信息
public User getUser(String userId) {
String key = "user:" + userId;
return (User) redisTemplate.opsForValue().get(key);
}
// 批量操作示例
public void batchSaveUsers(List<User> users) {
Map<String, User> userMap = users.stream()
.collect(Collectors.toMap(
user -> "user:" + user.getId(),
user -> user
));
redisTemplate.opsForValue().multiSet(userMap);
}
}
3.3.5 哈希标签使用示例
@Service
public class OrderService {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
// 使用哈希标签确保相关数据在同一个槽位
public void saveOrder(Order order) {
// 使用 {} 作为哈希标签
String key = "order:{user:" + order.getUserId() + "}:" + order.getOrderId();
redisTemplate.opsForValue().set(key, order);
}
// 获取用户的所有订单
public List<Order> getUserOrders(String userId) {
String pattern = "order:{user:" + userId + "}:*";
Set<String> keys = redisTemplate.keys(pattern);
return redisTemplate.opsForValue().multiGet(keys);
}
}
3.4 注意事项
键的设计:
- 使用哈希标签确保相关数据在同一个槽位
- 避免使用过长的键名
- 合理使用命名空间
批量操作:
- 使用 pipeline 减少网络往返
- 注意批量操作的数据量
- 考虑使用 multiSet/multiGet 等批量命令
异常处理:
- 处理 MOVED 重定向
- 处理 ASK 重定向
- 处理集群节点故障
性能优化:
- 使用连接池
- 合理设置超时时间
- 避免大键值对
4. 数据分片的优势
- 水平扩展:可以方便地添加新节点来扩展集群容量
- 负载均衡:数据被均匀分布到各个节点
- 高可用性:支持主从复制,提高系统可用性
- 自动故障转移:当节点故障时,集群可以自动进行故障转移
5. 数据分片的局限性
- 不支持多键操作:由于数据分布在不同节点,无法保证多键操作的原子性
- 事务限制:无法在多个节点间执行事务
- 键的迁移开销:在节点间迁移数据时会有一定的性能开销
- 客户端复杂度:需要客户端支持集群模式
6. 总结
Redis Cluster 的数据分片机制通过 CRC16 哈希算法和哈希槽的概念,实现了数据的自动分布和负载均衡。虽然存在一些限制,但通过合理的设计和优化,可以构建出高性能、高可用的分布式缓存系统。